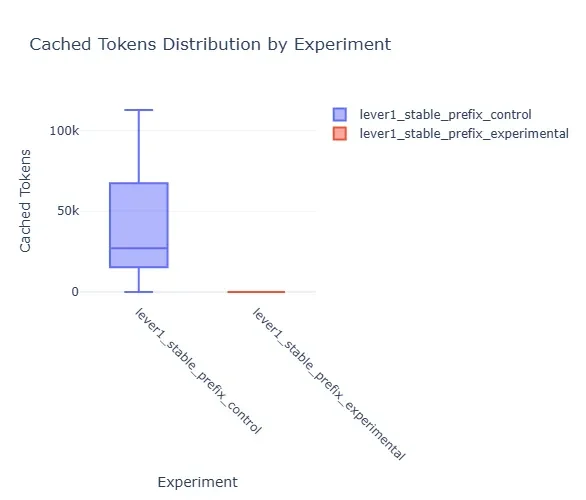
Recent discussions, notably featuring Dimitris Papailiopoulos, have illuminated a crucial aspect of how large language models (LLMs) manage their internal memory, specifically the Key-Value (KV) cache. The prevailing understanding, clarified by Papailiopoulos, posits that prefixes within transformer language models do not change. Instead, they are masked to maintain the integrity and validity of the KV cache. This revelation counters earlier assumptions of prefix modification and offers a more efficient operational model.
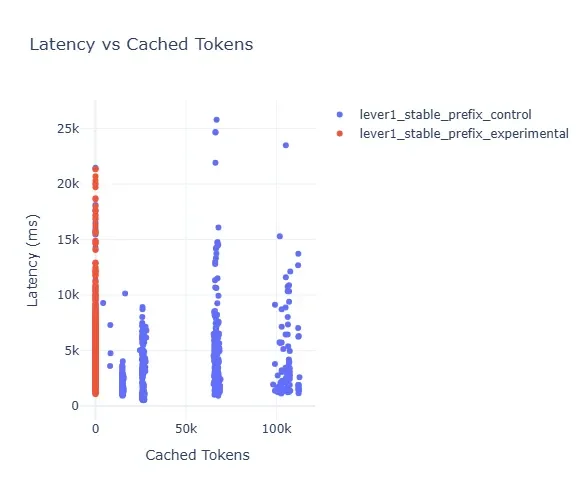
The core insight is that prefixes in LLM transformers remain fixed, with masking being the mechanism used to handle them rather than altering their content. This approach is critical for preserving the KV cache's effectiveness, a component vital for faster inference and managing computational load.
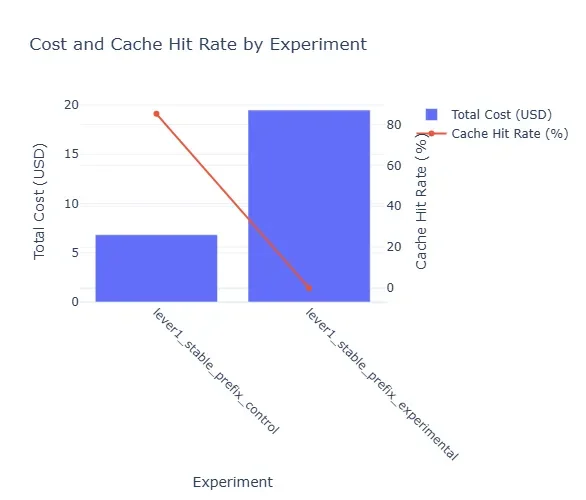
Engineered Efficiency: The Pursuit of Stable Prefixes
The practical implications of this KV cache behavior are becoming increasingly apparent. Researchers and developers are focusing on "cache-friendly context engineering," aiming to design prompts that align with the static nature of prefixes. This involves building prompts that "play nicely with the cache," thereby enabling predictably fast responses. The ultimate goal is to leverage stable prefixes to unlock significant latency improvements, with some estimations suggesting up to 65% gains. This translates directly into tangible benefits for both end-users, who experience quicker interactions, and for the operational side, by reducing computation time and associated costs.
Read More: Samsung Strike Limited by Court, May 21 Walkout Allowed
Several projects and research papers are exploring this domain:

KV-Cache Aware Prompt Engineering: This area of work directly addresses how to craft prompts that optimize KV cache usage. The emphasis is on creating prompts that capitalize on the fixed prefix structure.
DynamicKV: This research, published in Findings of the Association for Computational Linguistics: EMNLP 2025, delves into task-aware adaptive KV cache compression for LLMs dealing with long contexts. It suggests methods to compress the KV cache dynamically, a crucial step for efficiency in extended conversations or document processing.
KVFlow: Presented at NeurIPS 2025, this work focuses on efficient prefix caching to accelerate LLM-based multi-agent workflows. It highlights the importance of prefix caching in complex, multi-step AI interactions.
PAT (Prefix-Aware Attention): A November 2025 paper explores accelerating LLM decoding via prefix-aware attention, incorporating resource-efficient multi-tile kernels. This suggests architectural innovations to better handle prefix information.
HotPrefix: This research, slated for Proceedings of the ACM on Management of Data in September 2025, looks at hotness-aware KV cache scheduling for efficient prefix sharing. This indicates a move towards more intelligent management of cache resources based on usage patterns.
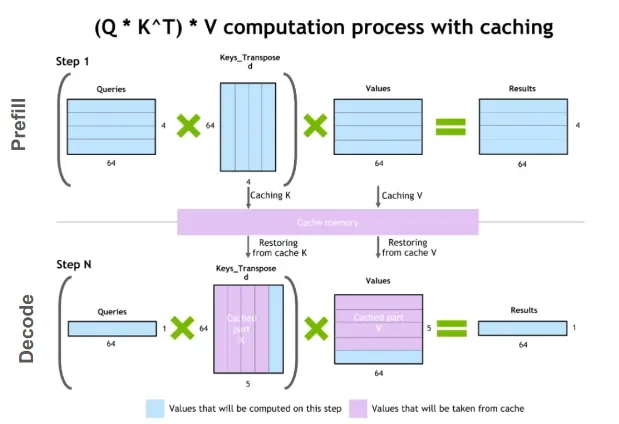
The Foundation: Understanding KV Cache and Prefix Handling
The KV cache is a fundamental component in transformer-based language models, acting as a memory to store intermediate computations. During the generation of text, the model processes input tokens sequentially. For each token, it computes Key (K) and Value (V) vectors, which are then used to generate the next token. Storing these K and V vectors in the KV cache avoids redundant computations for previously processed parts of the input sequence, significantly speeding up the inference process, especially for long texts.
Read More: AI Image Tools: Specialised vs General Chatbots in 2026
A "prefix" in this context typically refers to the initial part of the input sequence, often including system prompts, initial user queries, or context provided at the beginning of a conversation. Previously, the exact mechanism for handling these prefixes when the model needed to update or manage its state was less clear. The clarification that prefixes are masked rather than rewritten implies a more robust and efficient memory management strategy within LLMs. This distinction is vital for developers working on optimizing LLM performance, particularly in applications requiring low latency and high throughput. The ongoing research in this area underscores the dynamic evolution of LLM architecture and its practical deployment.