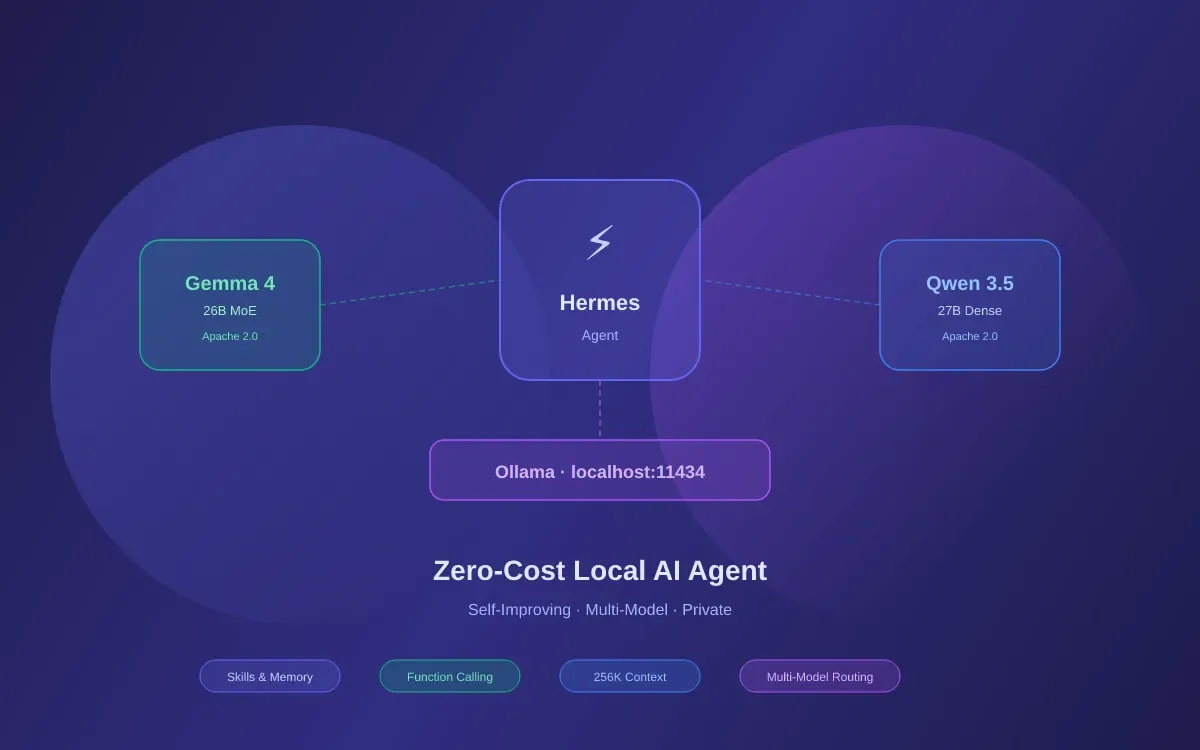
Hermes Agent, an open-source AI initiative, is gaining traction by enabling users to run sophisticated artificial intelligence models locally. This allows for greater control and potentially reduced costs compared to cloud-based solutions. The system leverages tools like llama.cpp and integrates with various large language models (LLMs), including Gemma 4 and Qwen 3.5, offering a flexible pathway for developers and enthusiasts to build AI-powered applications without relying on external services.

The core appeal of Hermes Agent lies in its capacity to operate independently of proprietary cloud infrastructure. This is achieved through a combination of self-hosted components, notably the llama-server binary built from the llama.cpp project, which supports GPU acceleration. Coupled with the Fircrawl self-hosted web scraping stack and a modular agent framework, Hermes provides a comprehensive local environment for AI tasks, from basic chat interfaces to complex tool utilization.
Read More: Forza Horizon 6 PC needs 16GB RAM and fast SSD

Infrastructure and Model Integration
The setup process, detailed in various guides, involves cloning repositories like local-hermes-agent and managing dependencies. Users are instructed to install llama.cpp, often via brew install llama.cpp, which provides the llama-server command. This server acts as an OpenAI-compatible inference endpoint, crucial for Hermes Agent's operation. The local-hermes-agent project, for instance, uses systemd user services to manage these components without requiring root privileges, ensuring services like llama-cpp and firecrawl run smoothly.

Downloading compatible LLM models is a key step. These models typically come in GGUF format, and their size dictates memory requirements. For example, running a Qwen3.5-9B model with a 128K context window on a machine with 16GB RAM can require approximately 10GB of memory, accounting for the model and its quantized KV cache. Users are guided to download specific model files, such as Qwen3.6-27B-Q4_K_M.gguf, and configure the .env file to point to the model's path, alongside other settings like context window size and idle timeouts for GPU memory management.
Read More: New AI Tools Help Check 231 Models in 2026

Operational Flexibility and Model Choices
Hermes Agent’s design emphasizes choice and interoperability. It can connect to Ollama, an existing platform for running local LLMs, via a custom endpoint configuration. This means Hermes can leverage models already managed by Ollama, including those like gemma4 (recommended for around 16GB VRAM) and qwen3.6 (requiring roughly 24GB VRAM). The agent supports any OpenAI-compatible endpoint, simplifying integration with various local LLM setups.
Beyond core functionality, Hermes Agent also facilitates connecting messaging applications such as Telegram, Discord, Slack, WhatsApp, Signal, or Email, enabling users to interact with their local models remotely. The agent's own command-line interface (hermes) allows for direct interaction, skill searching, and model switching, promoting an environment free from vendor lock-in. For users interested in specific models, guides highlight downloading models like Hermes 4 35B A3B in GGUF format, essential for agent-specific applications.
Read More: arXiv Bans Authors For 1 Year Over AI Errors In Papers
Background and Emerging Use Cases
The development and documentation around Hermes Agent suggest a move towards democratizing advanced AI capabilities. Projects like local-hermes-agent automate infrastructure deployment, making it easier for users with systems like WSL2 (Ubuntu) and compatible NVIDIA GPUs (e.g., RTX 4090 with 24GB VRAM) to set up a robust local AI environment. Instructions include necessary prerequisites like Docker Desktop with WSL2 backend, CUDA toolkit, and NVIDIA drivers.
Recent publications from April 2026 point to ongoing refinement and expansion of these capabilities. Articles discuss running local LLMs on Intel iGPUs using SYCL with llama.cpp, indicating efforts to broaden hardware support beyond NVIDIA GPUs. This includes managing potential dependency conflicts, such as with Intel's GPU drivers and specific oneAPI components. The MIT-licensed nature of Hermes Agent contributes to its accessibility, fostering a community around building production-ready AI applications locally.
Read More: AI Models: Small Models More Reliable Than Big Models For Specific Tasks





