Intel and SambaNova Systems have finalized a technical blueprint designed to offload specific AI inference tasks to distinct hardware units. By integrating GPUs, SambaNova RDUs (Reconfigurable Dataflow Units), and Intel Xeon 6 CPUs, the companies aim to bypass the performance constraints inherent in relying solely on graphics processing units for agentic AI workloads.
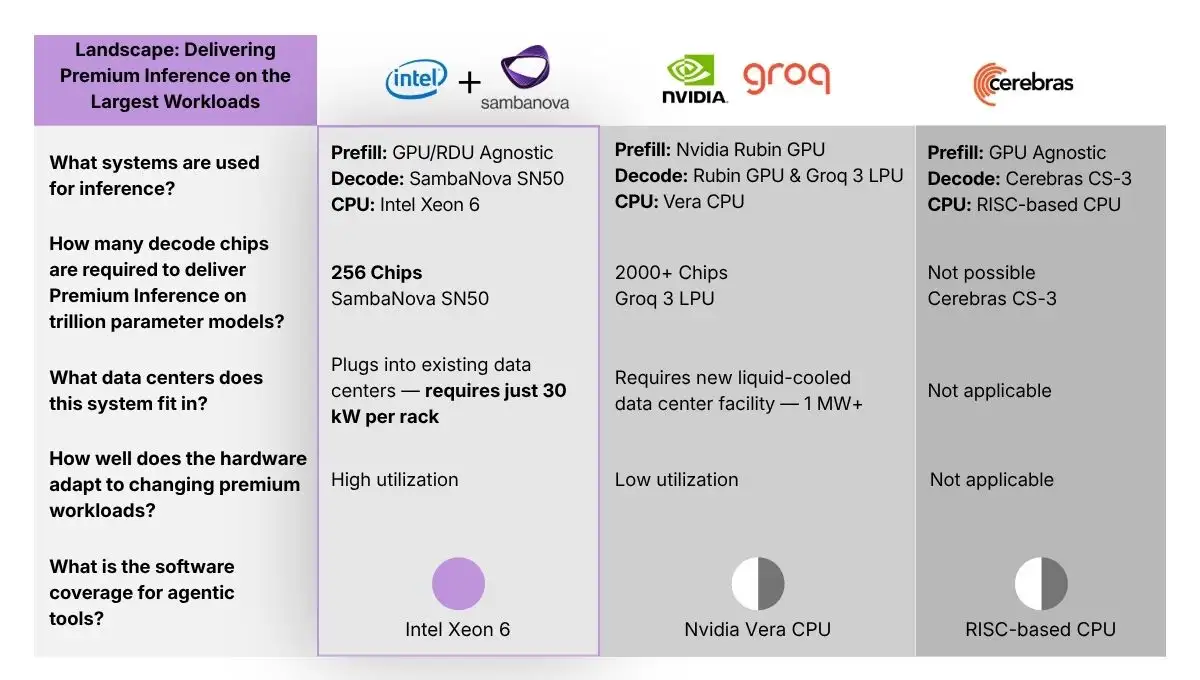
The architecture segments AI inference into specialized processing phases: GPUs manage initial 'prefill' (prompt processing), SambaNova SN50 RDUs handle high-throughput 'decode' (output generation), and Xeon 6 processors manage system orchestration, code execution, and tool coordination.

Division of Labor in AI Inference
The proposed stack attempts to stabilize the current friction between emerging AI agent workflows and existing data center environments. The roles are distributed as follows:

| Hardware Component | Primary Functional Role |
|---|---|
| GPU | Prefill (Compute-intensive prompt processing) |
| SambaNova SN50 RDU | Decode (Memory bandwidth-intensive token generation) |
| Intel Xeon 6 CPU | Control Plane (Orchestration, Agentic tool execution, APIs) |
According to the Intel-SambaNova collaboration, the system aims to utilize the x86 software ecosystem that remains the bedrock of modern enterprise infrastructure. SambaNova has committed to standardizing on Xeon 6 as the host platform for its RDU-based deployments.
Read More: New Email Security: SEG and API Tools Work Together
Strategic Context and Industry Positioning
The push toward this heterogeneous model follows a period where pure-GPU clusters have struggled with latency and cost efficiency as models transition from static chat to autonomous, "agentic" loops. Rodrigo Liang, CEO of SambaNova, characterizes the collaboration as a shift away from single-architecture dependency.
Performance Metrics: The partnership claims the Xeon 6 platform provides roughly 50% faster LLVM compilation speeds compared to Arm-based alternatives, with a 70% increase in vector database performance relative to previous x86 setups.
Availability: The integrated architecture is currently slated for enterprise and cloud-provider availability in the second half of 2026.
The design choice to leverage x86 represents a move to maintain software compatibility for firms that rely on legacy enterprise tooling while integrating newer, agentic AI pipelines. By isolating the 'decode' phase—which typically bottlenecks when hardware lacks specific memory bandwidth optimization—to the SN50 RDU, the companies are positioning themselves to challenge the dominance of existing monolithic GPU architectures in the AI inference market. This "three-chip" approach aims to optimize the total cost of ownership for deployments ranging from sovereign AI infrastructure to private cloud providers.
Read More: Qwen 3.5 AI Model Has Built-in Censorship Rules Found May 2026