
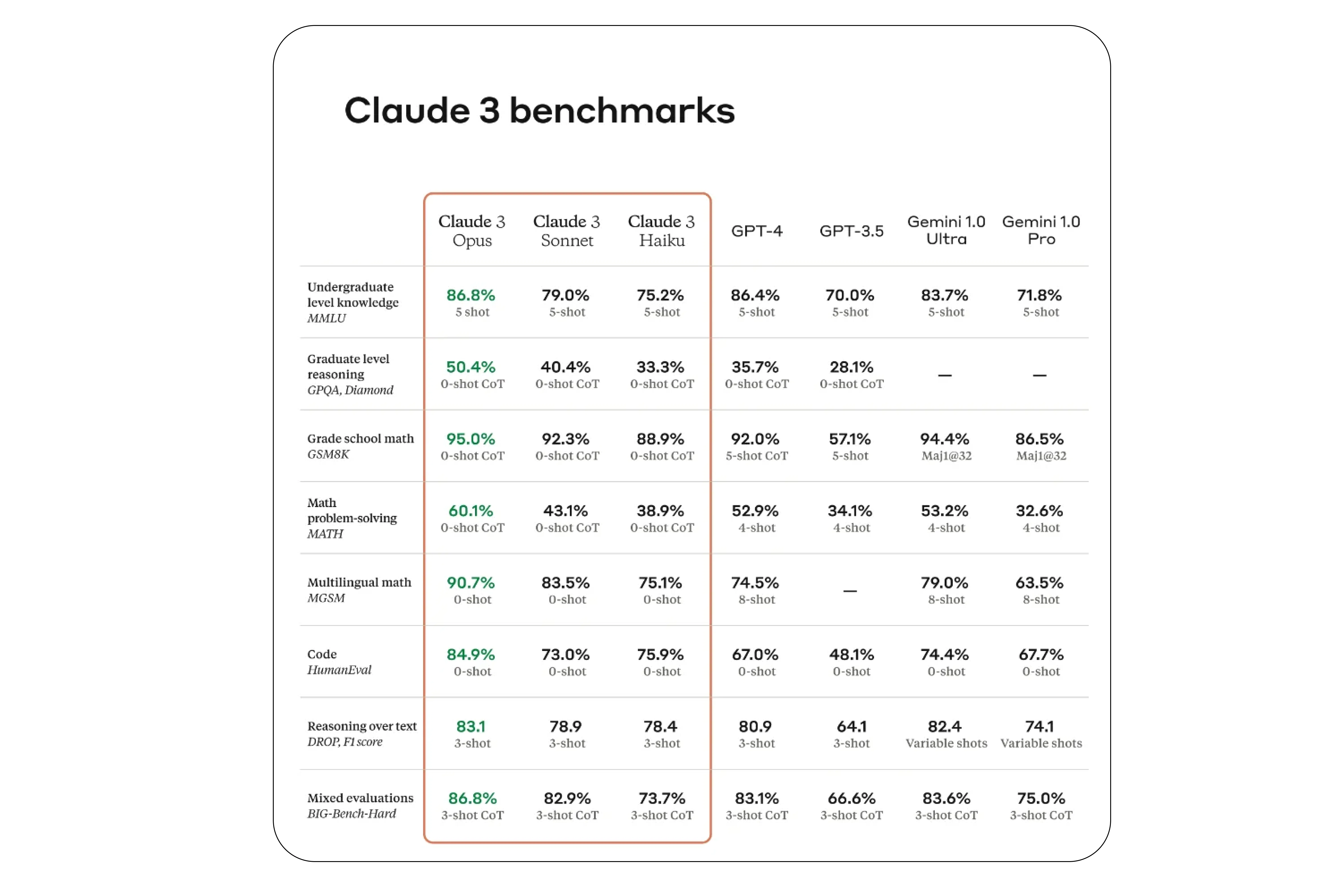
The push to quantify the prowess of AI agents in software development is creating a tangled web of benchmarks, each promising to illuminate model capabilities. Yet, a closer look reveals a field rife with potential pitfalls, particularly when relying on single leaderboard scores for production-level agent deployment. The core challenge lies in matching the abstract metrics of benchmarks to the messy reality of agents interacting with private codebases.

The evaluation of LLM agents for coding tasks is becoming a significant industry concern, leading to the development of specialized benchmarks designed to test various aspects of their performance. However, a recurring theme is the warning against over-reliance on single benchmark scores, with experts emphasizing the need to align benchmark tasks with the agent's actual operational domain.
The Illusion of Simple Metrics
Numerous benchmarks now exist, attempting to capture different facets of an AI's coding aptitude. These range from assessing the ability to detect code defects and translate code to generating text-to-code or even completing entire code repositories. Tools like 'HumanEval' and 'CodeElo' focus on pure code generation, while others, such as 'AgentBench', aim for a broader evaluation of agentic capabilities across multiple domains, including coding. 'SWE-bench', sourced from real-world GitHub issues, offers a more grounded approach to testing agents on practical software problems.
Read More: Fairfield Council Takes Legal Action After Hackers Steal Personal Data
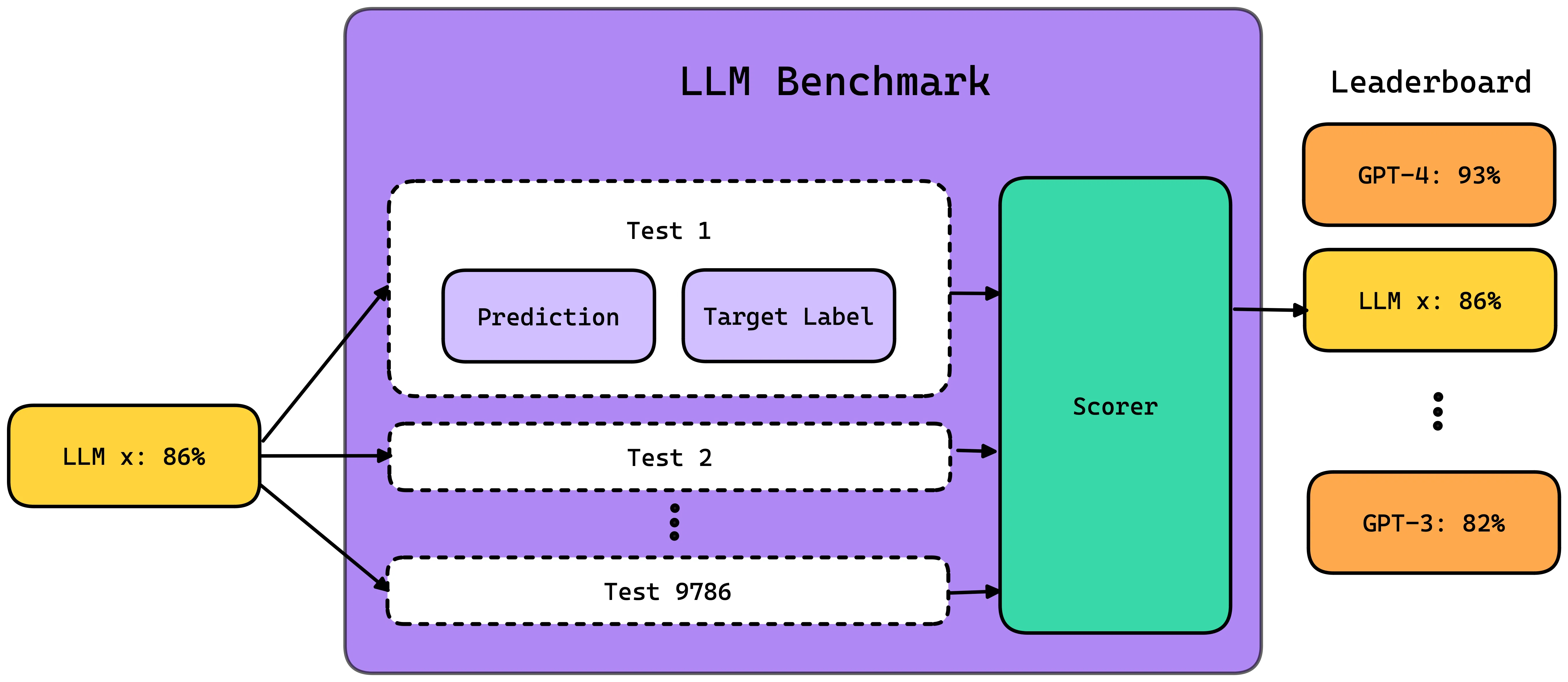
RepoBench scrutinizes repository-level code auto-completion.
Code Lingua tackles programming language translation.
HumanEval measures code generation proficiency.
CodeElo tests code generation in competitive programming contexts.
AgentBench evaluates general agentic behaviors across various domains, including coding.
SWE-bench uses real-world GitHub issues for evaluation.
DA-Code specifically targets agent-based data science tasks.
Navigating the Benchmark Maze
The sheer volume of benchmarks presents its own set of complications. A primary concern is the temptation to over-index on a single benchmark score. This simplistic approach fails to acknowledge that an agent's effectiveness is deeply tied to its specific application.
"Match your benchmark combination to what your agent actually does." - Blaxel Blog
This sentiment highlights a crucial disconnect: benchmarks often operate in controlled environments, whereas production agents are deployed within unique, private codebases where performance can diverge significantly from leaderboard standings.
Read More: Can 8GB VRAM run AI models? Yes, but with smaller models
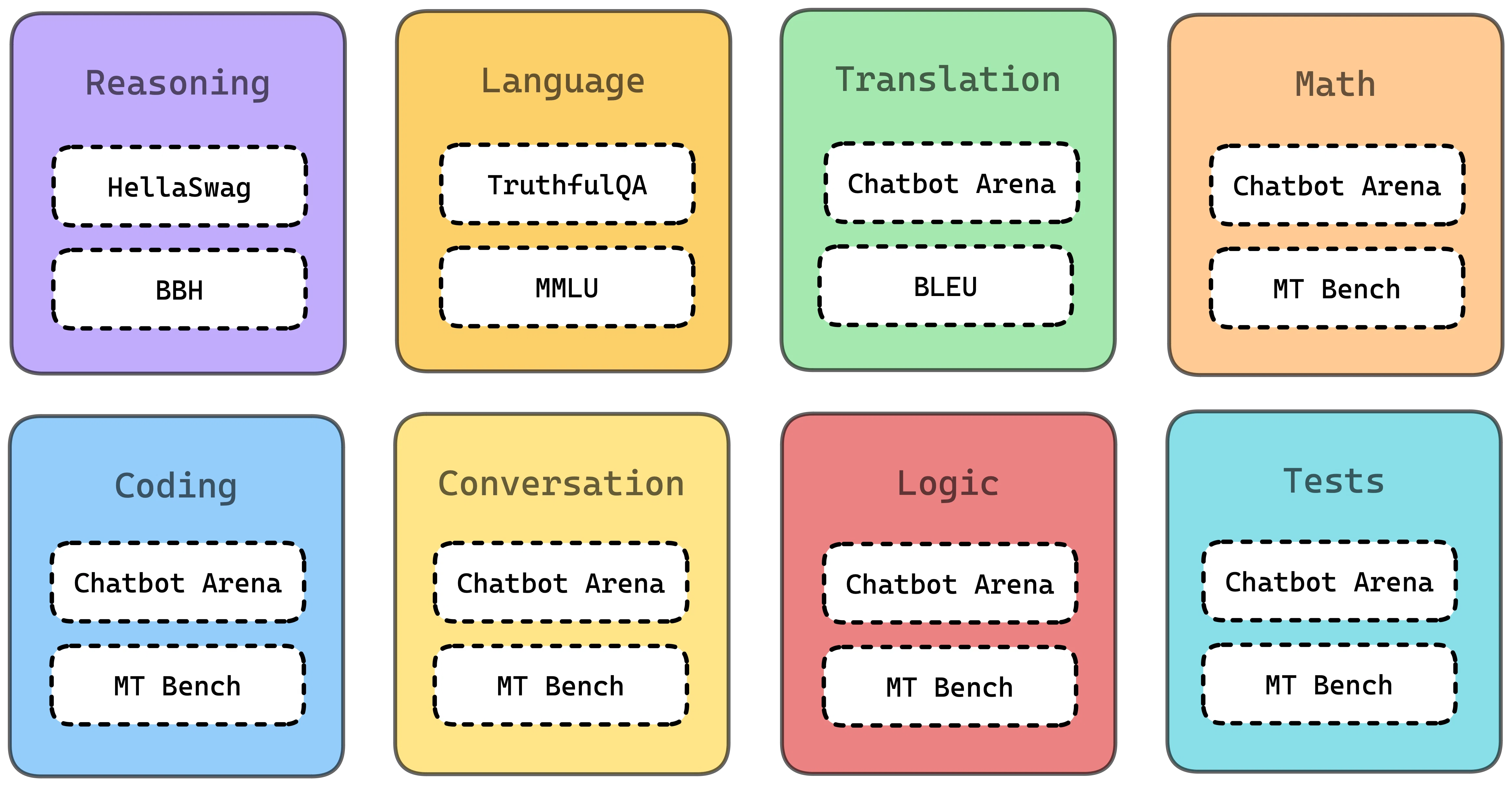
Frameworks like 'DeepEval' offer practical implementations of various benchmarks, including 'MMLU', 'HellaSwag', and 'BigBenchHard', allowing for more granular testing of specific capabilities such as understanding boolean expressions or causal judgment. These tools provide a structured way to engage with benchmark tasks, but they do not erase the fundamental challenge of real-world applicability.
The Agentic Dimension
Evaluating 'agentic behavior' is a distinct challenge from simply assessing code generation. This involves understanding how an AI agent interacts with its environment, selects appropriate tools, and executes complex workflows.
Tool Selection Quality, as measured by metrics like those used in the 'Agent Leaderboard', focuses on an agent's ability to pick the correct tool from a set of options and use its parameters effectively. This is distinct from mere code generation.
The complexity of these interactions is further illustrated by the operational requirements of some agent frameworks, such as 'AgentBench', which can involve setting up multiple Docker services and knowledge graph servers to simulate various task environments.
Background Noise
The landscape of LLM evaluation is constantly evolving, with ongoing discussions about the most reliable methods for assessing AI models. While many benchmarks exist for general LLM capabilities (e.g., 'MMLU', 'HellaSwag', 'BBH'), the specific demands of evaluating agents for software development are prompting the creation of more specialized tools. The ultimate goal appears to be moving beyond abstract scores towards a more pragmatic understanding of how these agents perform in practical, real-world scenarios, particularly within the confines of proprietary code.
Read More: Nvidia Plans Orbital AI Data Centers for Space Computing





