
As of 18/05/2026, the obsession with throughput in Large Language Model (LLM) serving has created a blind spot in performance monitoring. While raw data movement numbers appear healthy, they frequently mask systemic degradation. Industry standards are shifting focus toward goodput—the metric representing only the data that satisfies specific Service Level Objectives (SLOs).
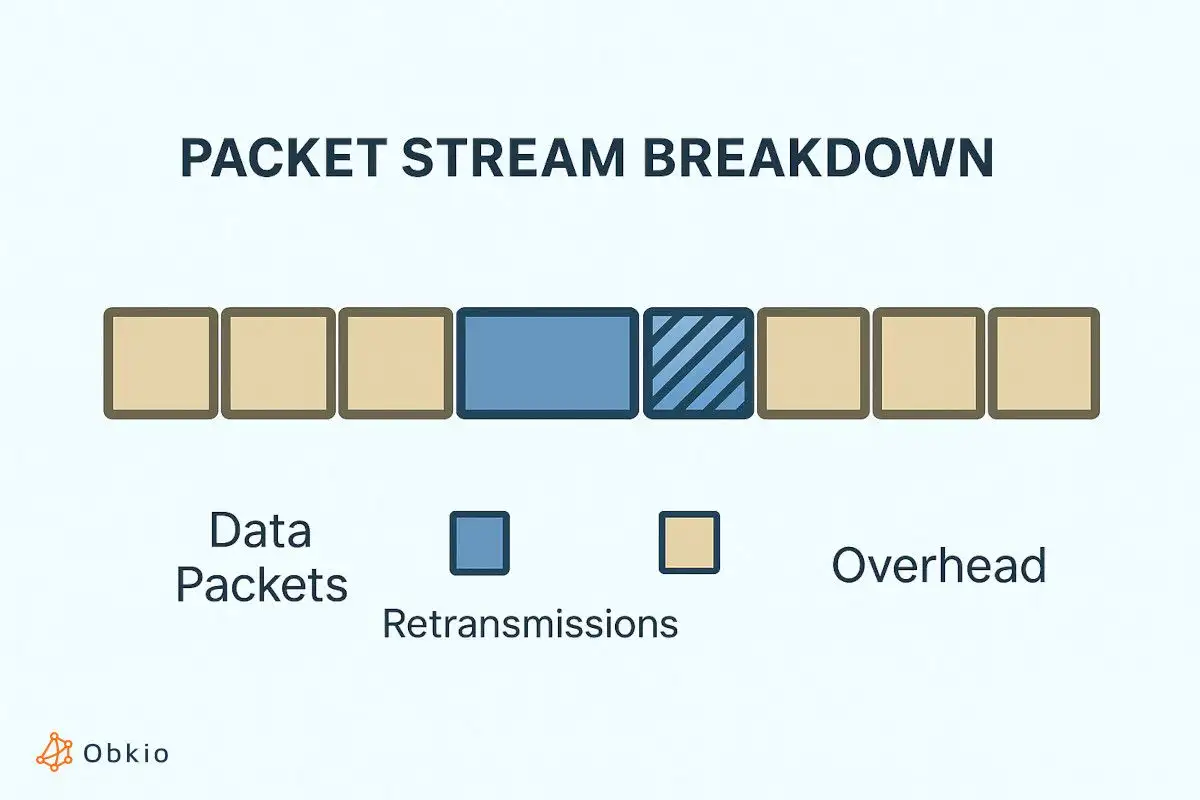
Goodput measures successful, useful application delivery; throughput measures total raw volume including overhead, errors, and retransmissions.
The Performance Gap
Engineers relying on throughput see a system processing 100% of capacity. However, when latency—specifically Time to First Token (TTFT)—exceeds predefined thresholds, those requests are effectively useless to the end user. Throughput remains high, but the goodput collapses.

| Metric | Focus | Includes Overhead/Errors |
|---|---|---|
| Throughput | Volume/Speed | Yes |
| Goodput | Utility/Success | No |
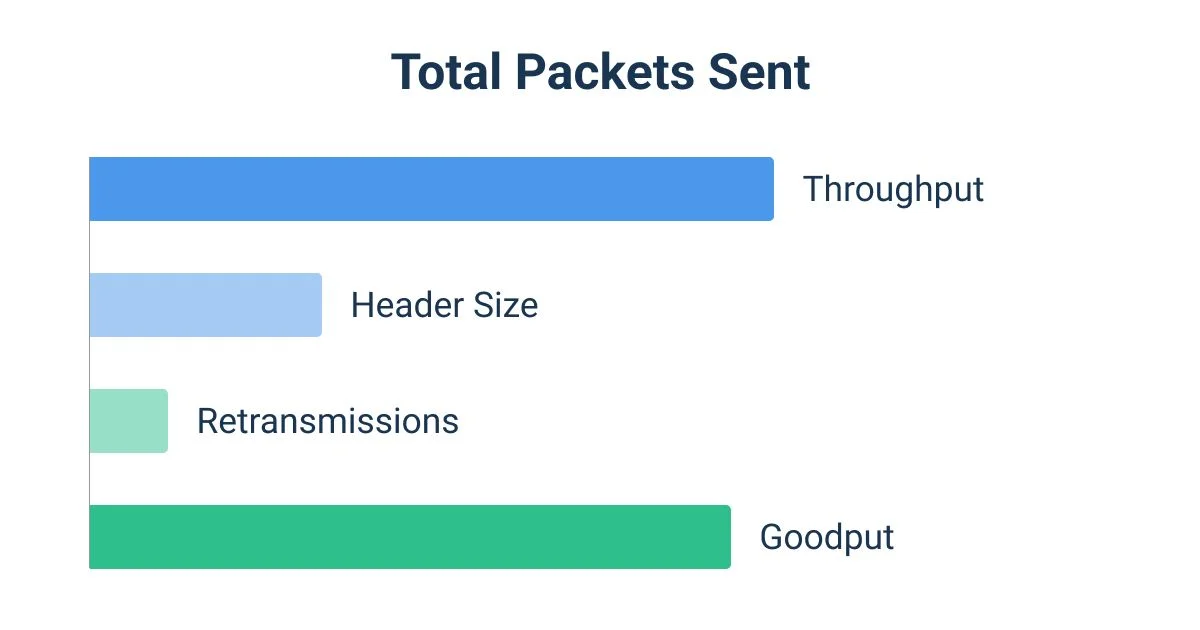
Protocol Overhead: Throughput counts control packets and retransmissions; goodput counts only the payload.
System Health: A healthy system maintains a narrow delta between throughput and goodput.
User Experience: User idle latency is often ignored in raw throughput counts, yet it determines if an LLM response is actionable or a failure.
Measurement and Instrumentation
Recent shifts in AI training efficiency underscore that efficiency is stack-aware. Training goodput is now viewed as the fraction of theoretical compute capacity converted into tangible progress, rather than simply how fast GPUs can cycle through tokens.
Read More: Chrome mimeHandler API lets extensions handle file types
"Goodput is only as credible as its instrumentation." — Emerging consensus in LLM benchmarking.
Distinguishing Technical Debt from Progress
The distinction is not merely semantic. In network performance and AI inference, throughput is a vanity metric when divorced from quality. If a server pushes 10,000 tokens per second but 40% arrive after the SLO threshold, the system is effectively under-performing.
Current investigation into LLM serving reveals that focusing solely on Time Per Output Token (TPOT) or Token Per Second (TPS) fails to account for the "useful" portion of a response. As LLMs become integrated into time-sensitive applications, goodput provides the necessary visibility into whether infrastructure upgrades translate into actual user value or merely increased technical overhead.



.jpg)



