Adapter Modules Offer Domain-Specific Speech Recognition with Minimal Resources
NVIDIA's Nemotron Speech ASR, a model designed for low-latency voice applications, can now be adapted to specific domains using a technique called 'adapter-based fine-tuning'. This method allows for domain-specific accuracy improvements with significantly less training data and computational power compared to full model retraining. The process involves adding small 'adapter' modules to the existing model, which are then trained on specialized datasets.
Adapter training enhances domain-specific performance metrics, such as Word Error Rate (WER), without degrading the model's general capabilities. This approach is particularly beneficial for use cases requiring high accuracy in specialized jargon or accents, such as earnings calls or medical dictation. The adapter modules add only a slight increase in inference latency, making them suitable for real-time applications.

Streamlined Adaptation Process
The adapter fine-tuning method, detailed in NVIDIA's NeMo framework tutorials, streamlines the adaptation process. Key steps include:
Read More: MIT Boron-Oxygen Molecule Acts as Builder in Chemical Reactions
Loading Models with Adapters: The base Nemotron model is loaded, and adapter modules are incorporated.
Enabling Adapters for Evaluation: Adapters are activated to assess performance on domain-specific test data. This allows for direct comparison between the base model and the adapted version.
Disabling Adapters for Base Model Evaluation: To confirm that general performance is maintained, adapters are turned off for evaluation on broader datasets.
Data Preprocessing: While full fine-tuning often involves extensive data augmentation, adapters may require less aggressive techniques. If overfitting is observed, augmentation intensity can be gradually increased.
The training process for adapters uses NeMo's standard scripts but with adapter-specific configurations. Parameters such as in_features, dim, and activation are set for the adapter modules, which are typically smaller than the base model's encoder dimensions.

Key Differences from Full Fine-Tuning
Adapter-based fine-tuning presents a distinct contrast to traditional full fine-tuning of ASR models:
| Feature | Adapter Training | Full Fine-Tuning |
|---|---|---|
| Learning Rate | Higher (e.g., 1e-3) | Lower (e.g., 1e-4) |
| Warmup Steps | Fewer (e.g., 100-500) | More (e.g., 1000-2000) |
| Training Steps | Fewer (e.g., 200-1000) | More (e.g., 10k-50k) |
| Batch Size | Smaller acceptable | Larger preferred |
| Vocabulary | Unchanged | Can be modified |
| Data Required | Minimal (~10 hours) | Significantly more |
| Compute Needs | Lower | Higher |
A critical limitation of adapter training is that it cannot modify the model's vocabulary. This means that if a new domain introduces entirely new terminology not present in the base model's lexicon, adapter fine-tuning alone will not address this.

Nemotron: A Foundation for Voice AI
The Nemotron Speech ASR model, specifically the nemotron-speech-streaming-en-0.6b variant, is built upon a Fast Conformer architecture with cache-aware inference for streaming applications. This architecture is engineered for low-latency transcription, making it suitable for real-time voice agents and live captioning. The model integrates punctuation and capitalization directly into its output.
Read More: Anthropic Refuses China Access to Latest AI Models
The broader 'Nemotron' family encompasses various open models and datasets from NVIDIA, covering pre-training, post-training, and reinforcement learning applications. This ecosystem aims to provide a comprehensive resource for developing agentic AI. Nemotron models are available through repositories like Hugging Face, with NVIDIA actively contributing to the open-source community.

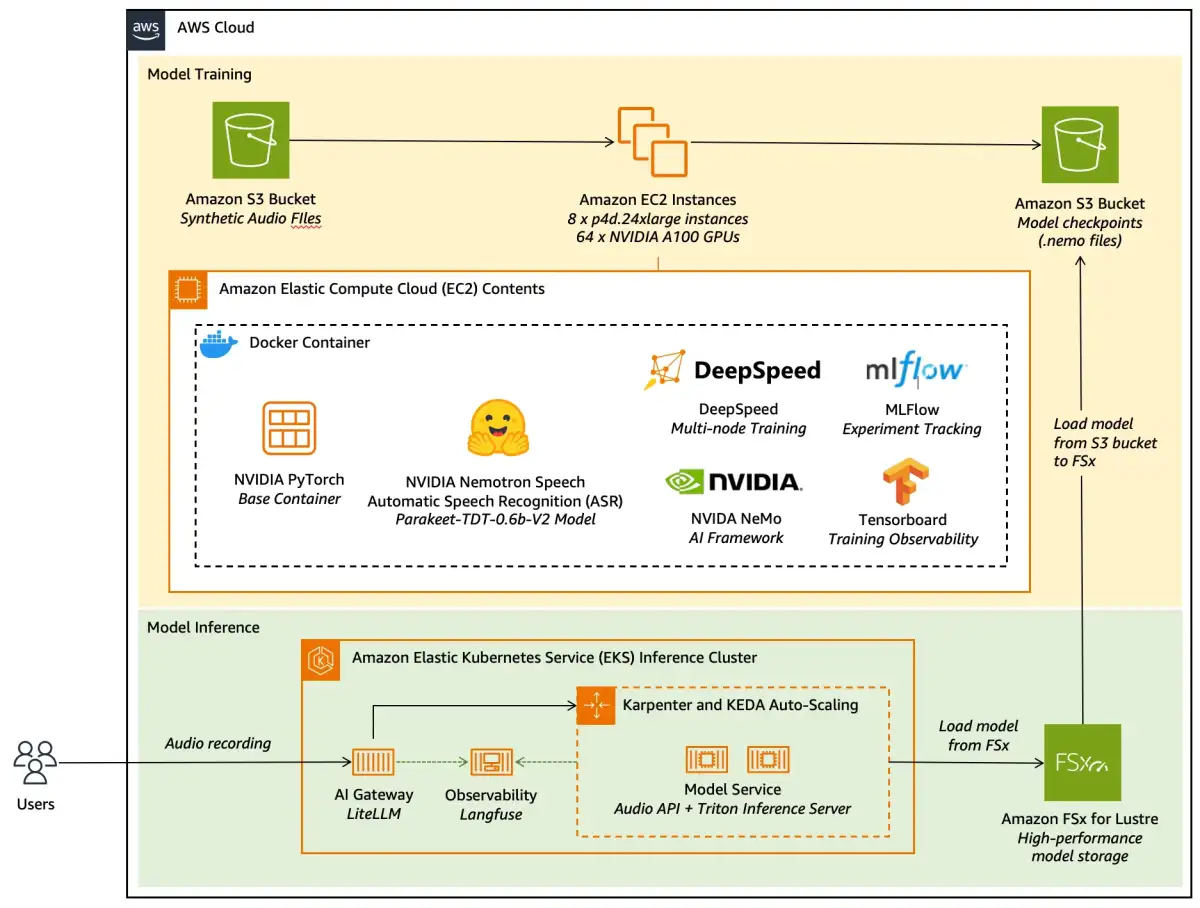
The NVIDIA NeMo framework provides the tools and libraries necessary for these adaptation tasks. Users can install NeMo via pip, with specific packages available for ASR, Text-to-Speech (TTS), and multimodal applications. NVIDIA also offers pre-built Docker containers optimized for NeMo, simplifying the setup for researchers and developers.
The release of Nemotron Speech ASR and its adaptable nature aligns with the increasing demand for sophisticated voice AI solutions. Projects like building voice agents with models such as Nemotron Speech ASR, Nemotron 3 Nano LLM, and NVIDIA Magpie TTS demonstrate the practical application of these technologies.