
NVIDIA's CUDA framework, the backbone of modern AI and scientific computation on graphics processing units (GPUs), is facing persistent questions about its dominance and proprietary nature. While it underpins significant advancements in fields like large language models (LLMs) and computer vision, its closed-source ecosystem prompts ongoing debate regarding vendor dependency.
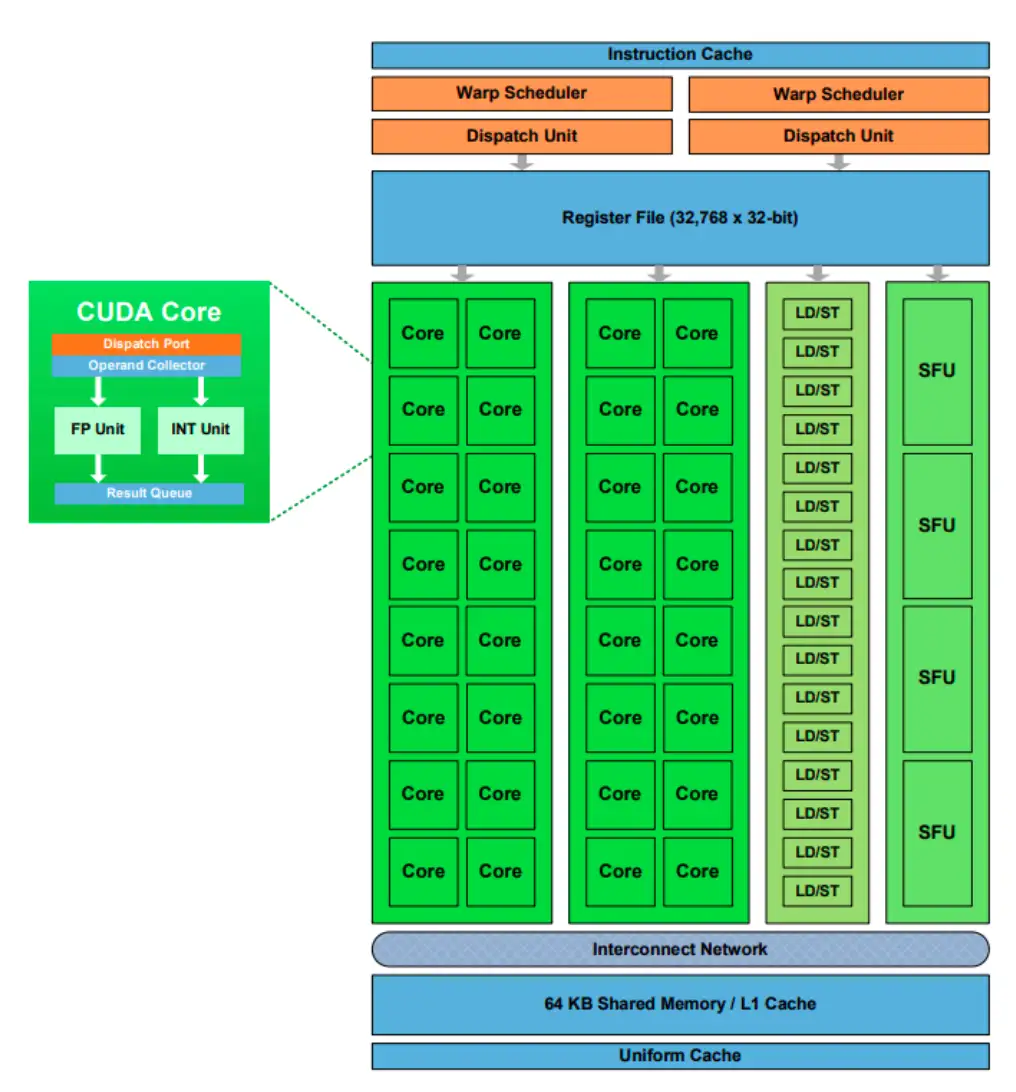
The core functionality of CUDA revolves around its parallel programming model, utilizing kernels – functions designed to run concurrently across a GPU's numerous processing units (Streaming Multiprocessors, or SMs). This architecture is particularly suited for the linear algebra operations, such as matrix multiplications and vector additions, that form the bedrock of neural networks.

Development and Implementation
NVIDIA's proprietary CUDA Toolkit provides developers with a suite of tools and libraries, including the NVIDIA CUDA Compiler (NVCC), for optimizing computations on NVIDIA GPUs. Developers often interface with CUDA through higher-level frameworks like PyTorch and TensorFlow, which are compiled for specific CUDA versions. Compatibility between these components is crucial, with installation guides emphasizing the need to align NVIDIA drivers, CUDA Toolkit versions, and the chosen deep learning framework. For instance, a driver version like 560 might necessitate a CUDA 12.6 Toolkit.
Read More: gRPC vs REST: Which API is better for your app in 2026?
Python bindings offer simplified access to CUDA's power. Libraries like PyCUDA and CuPy provide ways to execute GPU-accelerated operations directly from Python, mimicking familiar interfaces like NumPy. PyCUDA facilitates the direct compilation and execution of CUDA kernels, while CuPy aims to be a drop-in replacement for NumPy, performing operations on the GPU.

Underlying Architecture and Ecosystem
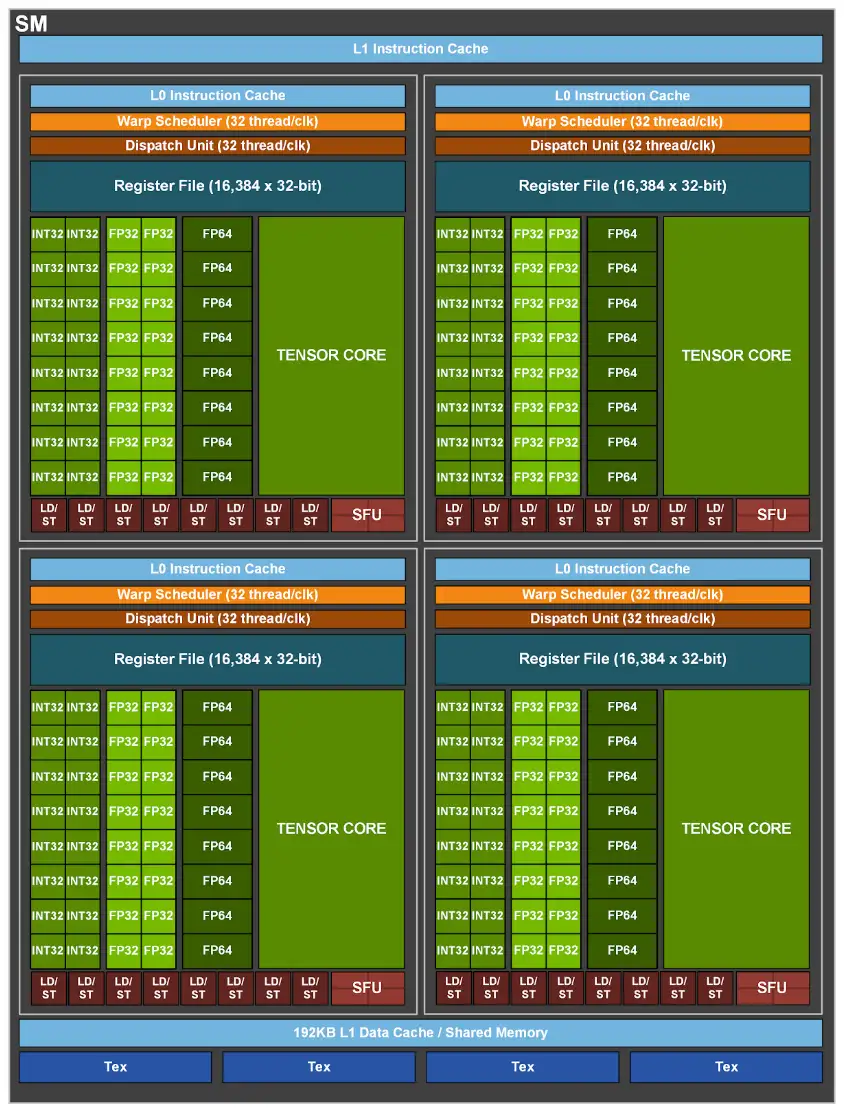
The efficiency of CUDA is tied to the physical architecture of NVIDIA GPUs, which are built with many Streaming Multiprocessors (SMs), each containing numerous CUDA Cores (Streaming Processors). This parallel structure, combined with high-speed onboard memory (VRAM) and significant memory bandwidth, enables rapid data processing.
Read More: Sintrone ABOX-5210G for Edge AI GPU Computing Released
The CUDA Software Ecosystem extends beyond the core toolkit. It includes utilities for profiling and debugging, allowing developers to analyze and optimize GPU performance. NVIDIA also offers a free CUDA Toolkit and associated training resources, fostering a large community of developers who leverage the platform for diverse projects.
Alternatives and Dependency Concerns
The pervasive influence of CUDA has spurred discussions about the reliance on a single vendor. While specific alternatives are not detailed in the provided material, the very mention of these questions highlights a desire for greater openness and interoperability within the high-performance computing and AI sectors. The integration of frameworks like PyTorch with platforms such as vLLM for improved developer experience on specific architectures (like aarch64) also points to a continuous effort to enhance accessibility and performance, irrespective of the underlying GPU acceleration technology.
Read More: Social Media Overuse Linked to Lower Wellbeing
Historical Context
CUDA, an acronym for Compute Unified Device Architecture, was introduced by NVIDIA to leverage the parallel processing capabilities of their graphics cards for scientific and general-purpose computing. This innovation effectively transformed GPUs from mere graphics rendering devices into powerful accelerators, fundamentally changing the landscape of AI research and development.


.png)


