
The landscape of measuring artificial intelligence performance is undergoing a notable shift, with the MLPerf benchmark suite now placing significant emphasis on latency for large language models (LLMs). This evolution, detailed in recent publications and announcements from MLCommons, reflects a broader industry move toward evaluating AI systems not just on raw throughput, but on their responsiveness and speed in real-world applications.

MLPerf Inference v5.0 marked a pivotal moment, with LLMs surpassing traditional workloads like ResNet-50 in submission frequency, signaling their dominance in current AI development. This surge in LLM-centric benchmarking underscores the critical need for nuanced performance metrics beyond simple output rates.

The Latency Conundrum in LLM Inference
Understanding LLM performance requires dissecting its inference process into two distinct phases: prefill and generation. While prompt processing, or prefill, can operate without interruption, the generation phase is inherently sequential and often memory-bound. This distinction is crucial when assessing how quickly an LLM can deliver its output.
Read More: cuDSS System May Add Support For Small Distributed Systems
"The generation phase is still sequential and memory bound." - EDN Magazine
Recent benchmark results have highlighted specific latency metrics for prominent LLMs. For instance, models like Claude 4.5 Sonnet and GPT-5.2 are being measured by their Time To First Token (TTFT) and Time Per Output Token (TPOT). Recent data indicates TTFTs ranging from 0.60 seconds (GPT-5.2) to 2 seconds (Claude 4.5 Sonnet), with TPOTs around 0.020-0.035 seconds.
MLPerf's Shifting Focus
Historically, MLPerf has focused on throughput-oriented tests. However, recent iterations, particularly MLPerf Inference v4.0, introduced the first LLM benchmark using Meta's Llama 2 70B. This was followed by benchmarks in v5.0 and v5.1 featuring more advanced models like Llama 3.1 8B and Llama 3.1 405B Instruct.
MLPerf Inference v5.1, released in September 2025, specifically introduced benchmarks for smaller LLMs like Llama 3.1 8B, detailing latency thresholds of TTFT ≤ 2 seconds and TPOT ≤ 100 milliseconds for its server scenario.
The selection of models like Llama 3.1 405B Instruct, with its significantly larger context window of 128,000 tokens compared to Llama 2 70B's 4,096, demonstrates a push towards evaluating capabilities in long-context comprehension.
MLPerf Inference v6.0 is set to expand this further, measuring performance across a variety of LLM architectures, including dense and mixture-of-expert (MoE) models, alongside other AI tasks.
| Benchmark Version | Key LLM Introduced | Notable Metrics Emphasis | Publication Date |
|---|---|---|---|
| Inference v4.0 | Llama 2 70B | Initial LLM inclusion | (Implicitly 2024) |
| Inference v5.0 | Llama 3.1 405B | Throughput & TTFT/TPOT | September 2, 2025 |
| Inference v5.1 | Llama 3.1 8B | Latency (TTFT/TPOT) critical | September 9, 2025 |
| Inference v6.0 | (Various LLMs) | Broader LLM architectures | (Upcoming/Implied) |
Hardware and System Performance
The drive for better LLM inference performance is also pushing hardware advancements. Recent reports highlight significant speedups on platforms like NVIDIA's Blackwell, with systems achieving substantial throughput gains on benchmarks like Llama 2 70B and Llama 3.1 405B. For instance, the eight-GPU B200 system reportedly achieved 3.1x higher throughput on the Llama 2 70B interactive benchmark compared to earlier NVIDIA hardware.
Read More: AI Company Anthropic Asks for Pause in Fast AI Growth
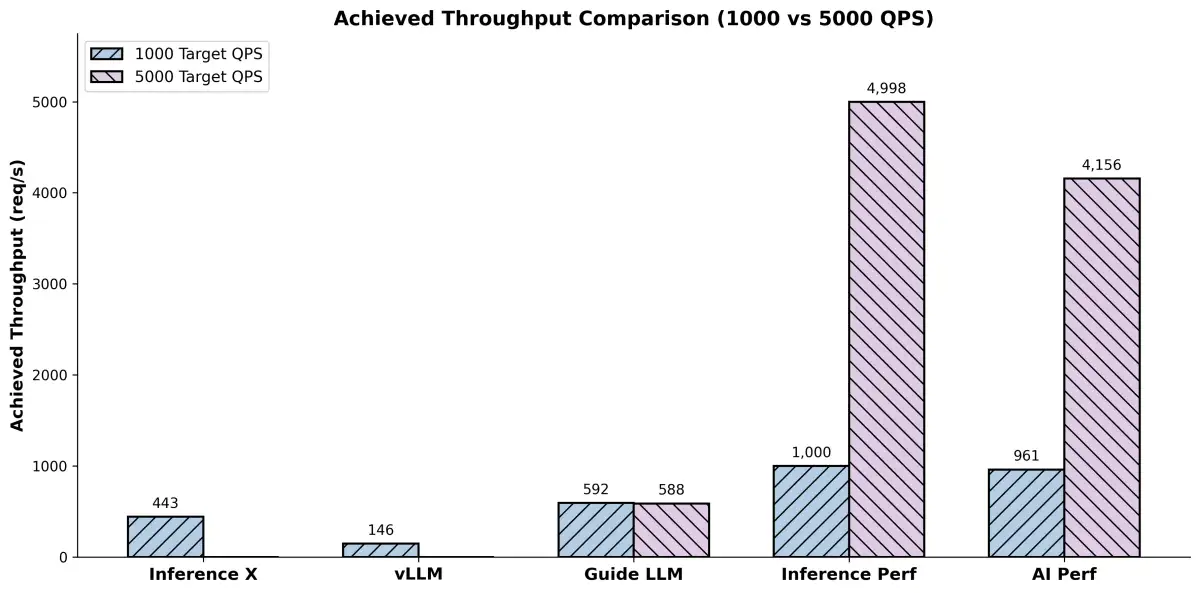
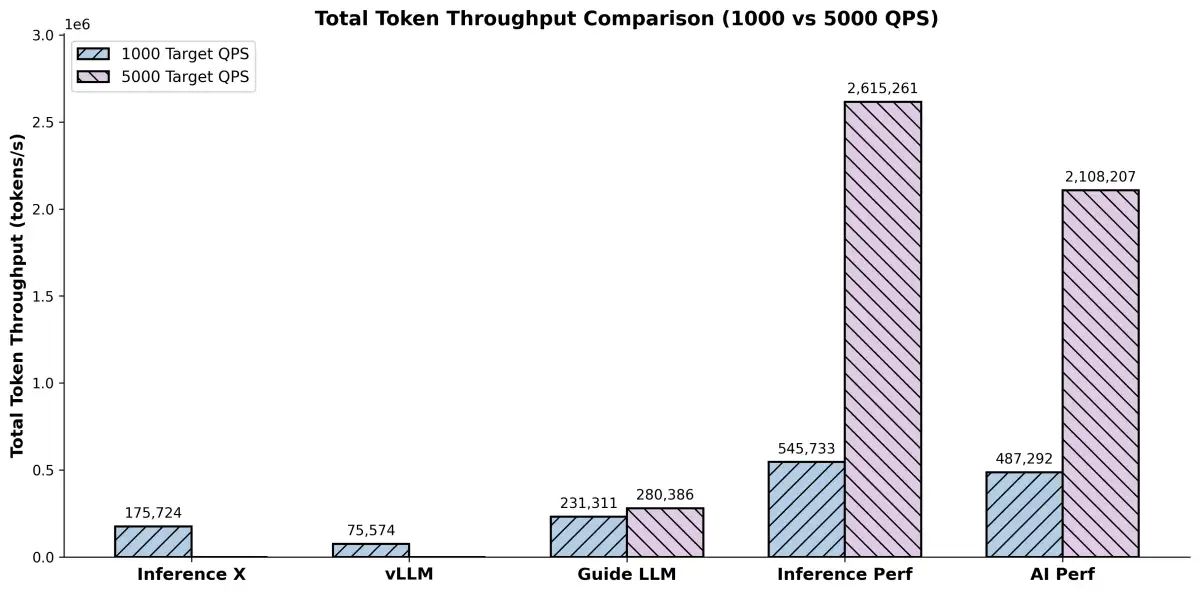
Furthermore, the integration of LLM inference into production systems is a growing concern. Solutions like Red Hat Enterprise Linux are being optimized for LLM inference, with efforts focusing on delivering hardware-agnostic, production-ready platforms that ensure reproducible and high-throughput performance, often leveraging frameworks like vLLM.
Background: The MLPerf Initiative
MLPerf, managed by MLCommons, is an industry consortium aimed at establishing standardized benchmarks for measuring machine learning performance. It began as a chip-level benchmark and has since expanded to encompass system-level performance, reflecting the growing complexity of AI deployment. The suite covers various categories, including datacenter and edge systems, and assesses performance across diverse workloads such as image classification, object detection, and increasingly, complex language tasks. The ultimate goal is to provide a reliable and transparent method for comparing AI hardware and software capabilities.



