Core Operations and Measurement Complexities
At its heart, the processing of language models, known as 'inference', hinges on a sequential, token-by-token generation. Each new piece of information, a 'token', is directly dependent on every preceding one. This process is not uniform; it divides into two distinct phases. The initial phase is measured by 'Time to First Token' (TTFT), indicating the wait for the very first output after a request is made. Following this, 'Time per Output Token' (TPOT) quantifies the ongoing generation speed, averaging the duration for each subsequent token. Measures like 'Tokens per Second' (TPS) capture the overall throughput, encompassing both input processing and the sequential output generation across multiple requests. Understanding which specific resource becomes a constraint is paramount for effective 'optimization'.
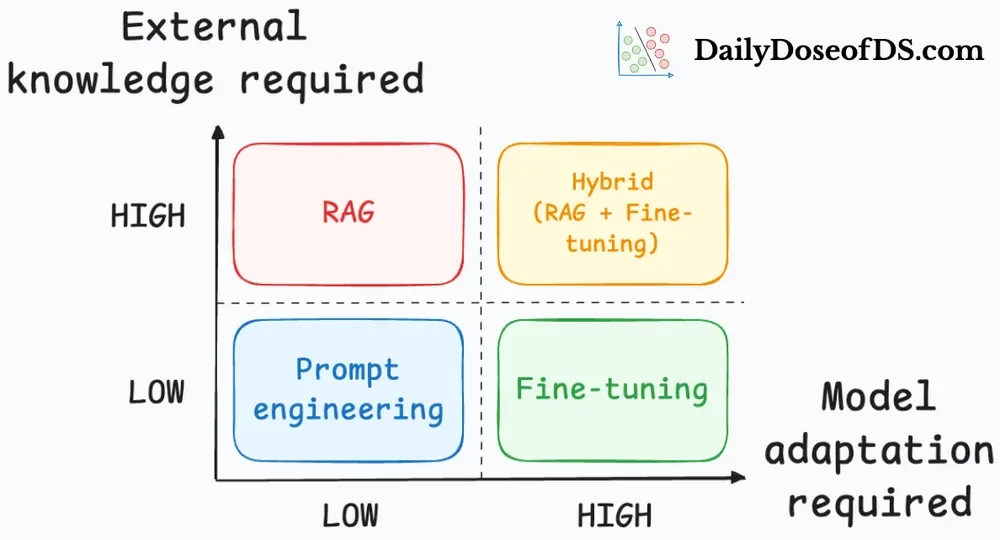
Systemic Hurdles and Strategic Adjustments
The drive for 'faster' and 'cheaper' large language model operations exposes fundamental system limitations. As AI systems scale across diverse environments, from cloud infrastructure to local servers, inference emerges as the principal bottleneck. This reality intensifies with larger models, extended 'context windows' (the amount of prior information a model considers), and the demands of serving multiple users simultaneously. Unpredictable traffic patterns exert relentless pressure on speed, output quantity, and the financial outlay for computing power, particularly GPUs. Repeatedly, the same performance failures surface across different operational setups. Nevertheless, judicious application of specific inference strategies promises to extract substantially more capability from existing hardware, leading to improvements in initial response times, overall output volume, the number of concurrent operations, and the cost associated with each generated token.
Read More: MIT Boron-Oxygen Molecule Acts as Builder in Chemical Reactions
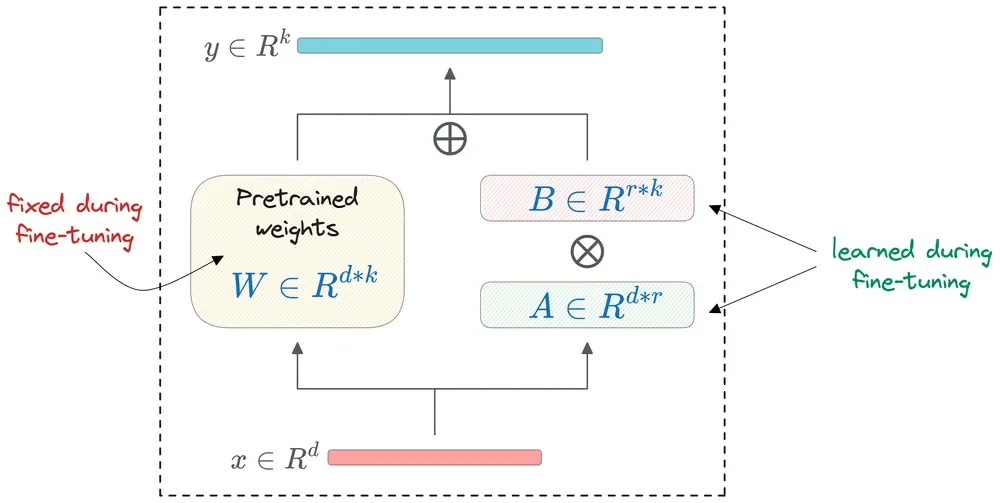
Advanced Techniques and Infrastructural Plays
Beyond fundamental speed metrics, various advanced techniques aim to refine LLM inference. 'Quantization', for instance, shrinks the digital footprint of model weights and associated data, often by reducing numerical precision, thereby making models smaller and potentially faster. 'Knowledge Distillation' offers a method where a smaller, more agile 'student' model learns from a larger, more complex 'teacher' model. 'Speculative Decoding' employs a smaller, rapid model to propose tokens, which are then verified by a more capable, but slower, model, potentially accelerating the overall process.
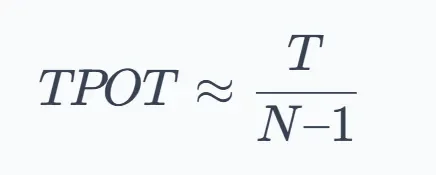
On the infrastructural front, managing computational resources becomes key. Techniques like 'GPU Partitioning', including NVIDIA's 'MIG' (Multi-Instance GPU) and fractional GPU allocation, aim to prevent underutilization of expensive hardware, especially for less demanding tasks or smaller models. Orchestration layers, such as 'Ray Serve' for model serving and 'AKS' (Azure Kubernetes Service) for infrastructure management, play critical roles in handling request routing, automatic scaling, grouping incoming requests ('batching'), and distributing models across available computing resources. The efficient serving of multiple, slightly different model variations, such as 'multi-LoRA' setups, is also a focus within these frameworks.
Read More: Anthropic Refuses China Access to Latest AI Models

Background Considerations
The increasing ubiquity of Large Language Models (LLMs) across applications like chatbots, code generation, and translation has amplified the importance of their operational efficiency. The underlying mechanism for how these models generate output in real-time is termed 'inference'. To tackle the inherent limitations, a suite of optimization methods is continuously explored. These range from internal model adjustments to broader system-level accelerations. The core challenge lies in balancing computational demands, memory constraints, and latency requirements. Techniques like 'mixed precision'—using different numerical formats for various parts of the computation—also influence inference speed.
LLM inference fundamentally relies on 'autoregressive' models, which generate output sequentially. The efficiency of this generation is frequently constrained by memory bandwidth, particularly concerning the model's 'weights'—the parameters learned during training. Strategies to address this include parallelizing model execution by distributing these weights across multiple processors. The 'KV cache', a mechanism that stores intermediate results from previous calculations, is another critical component that, when managed effectively, can significantly speed up the inference process by avoiding redundant computations, especially for longer inputs which themselves impose a quadratic cost on attention computations.