Recent advancements reveal a growing convergence of Large Language Models (LLMs) with diffusion-based image generation techniques, aiming to achieve more nuanced and accurate visual outputs. This pairing seeks to overcome limitations in prompt adherence, a persistent challenge in translating textual descriptions into precise imagery.
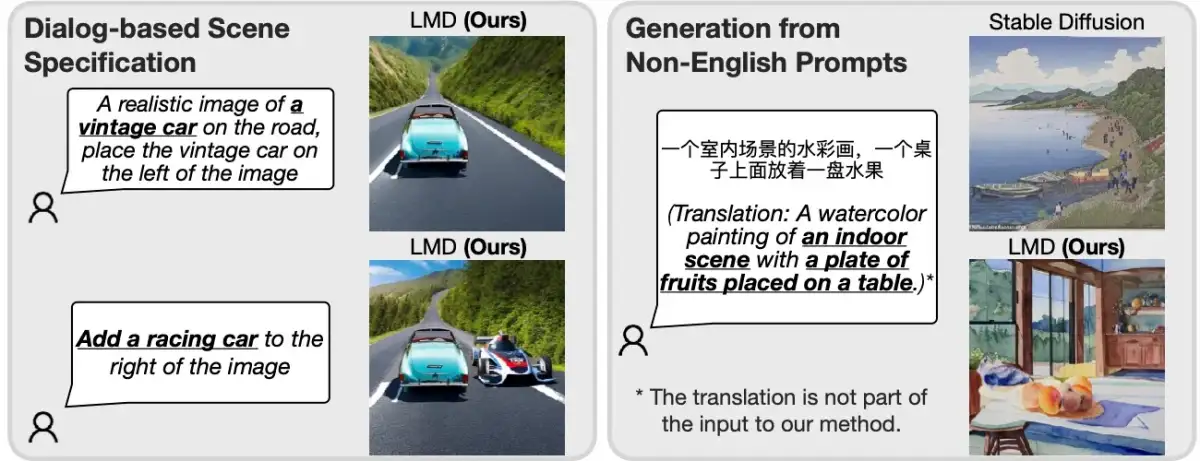
The core idea involves using LLMs to refine or structure prompts before they are fed into diffusion models, leading to improved understanding and execution of complex visual instructions. This approach, exemplified by frameworks like LLM-grounded Diffusion (LMD), reportedly bypasses the need to retrain either the LLM or the diffusion model itself, relying instead on frozen, pre-trained components.
Bridging Text and Pixels: A Methodological Shift
The foundational concept involves a multi-stage process: a textual prompt is first processed by an LLM, which then generates an intermediate representation – often described as an image layout or structured prompt. This refined input is subsequently utilized by a diffusion model, such as Stable Diffusion, to generate the final image.
Read More: AI Math Test Shows AI Hallucinates Solutions for Unsolvable Problems
This method is presented as a way to enhance prompt understanding, ensuring that generated images more closely match the user's descriptive intent.
LLM-grounded Diffusion (LMD) is a prominent example, reportedly offering superior prompt comprehension in specific scenarios compared to standard text-to-image models.
Further iterations and variations, like LMD+, have explored integrating outputs from various LLMs, including GPT-3.5 and GPT-4, and even open-sourced models like StableBeluga2 and Mixtral-8x7B-Instruct-v0.1, to assess their impact on generation quality.
Towards More Precise Visuals
Research efforts, such as those documented in the 'Proceedings of the Conference on Text-to-Image Synthesis', delve into integrating LLMs with diffusion techniques for advanced text-to-image synthesis. This suggests a trajectory towards more sophisticated image creation capabilities.
Systems like ELLA Models, developed by Kinomoto Magazine, specifically target improving prompt adherence for local diffusion models. This workflow aims to enable the creation of more complex and precise images by leveraging LLMs to enhance prompt interpretation.
The practical application of these methods is evident in code repositories and project pages, demonstrating how to run generation scripts with different LLM configurations and diffusion baselines, including methods like MultiDiffusion, Backward Guidance, Boxdiff, and GLIGEN.
Evaluation metrics are being employed to assess the effectiveness of these integrated systems, with some noting the use of specific configurations, like ignoring negative prompts in Stable Diffusion v1.5 to allow it to function as a baseline.
A Developing Landscape
The underlying research spans academic conferences and preprint archives, indicating a dynamic field of inquiry.
LLM-grounded Diffusion (LMD) was detailed in a 2023 publication, with a subsequent mention on platforms like arXiv.
More recent work, such as the ELLA Models workflow, appeared in April 2024, showcasing ongoing development and application in community-driven platforms like ComfyUI.
A 2026 publication in 'Advances in Neural Information Processing Systems' points to continued academic engagement with these integrated techniques.




