
Recent documentation updates reveal a subtle but significant shift in how specialized computing clusters, particularly those leveraging GPUs, are being managed and deployed. The focus appears to be moving from mere provisioning of hardware to sophisticated 'orchestration' – a method of dynamically managing workloads and resources across the entire AI development lifecycle.
NVIDIA's "Run:ai" platform is highlighted as a system designed to accelerate these AI operations. It promises to maximize GPU efficiency and scale workloads with what it terms "zero manual effort." The documentation points to integrated approaches for hybrid AI infrastructures, suggesting a move away from siloed deployments towards more fluid, interconnected environments.
Resource Management and Instance Control
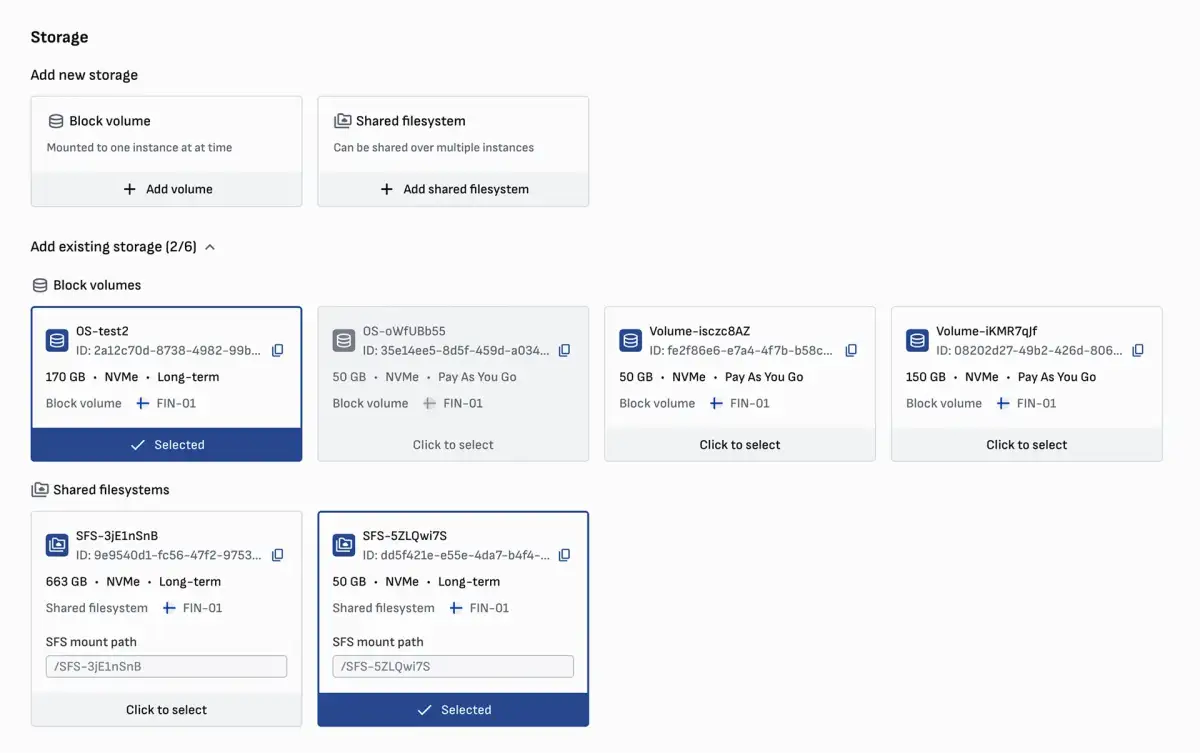
Tools like those described in Verda's documentation offer granular control over individual computing instances, whether they are CPU or GPU-based. The ability to list, describe, and manage the state of these instances – including starting, shutting down gracefully or forcefully, hibernating, and deleting them – indicates a need for precise resource allocation and deallocation.
Read More: Snowflake Adds AI Agents to Data Cloud Platform in 2026
Instance Lifecycle: Verda's CLI (Command Line Interface) details commands for managing the entire lifecycle of an instance.
Resource Availability: Users can check which instance types are available in specific locations, hinting at geographic distribution and potential resource contention.
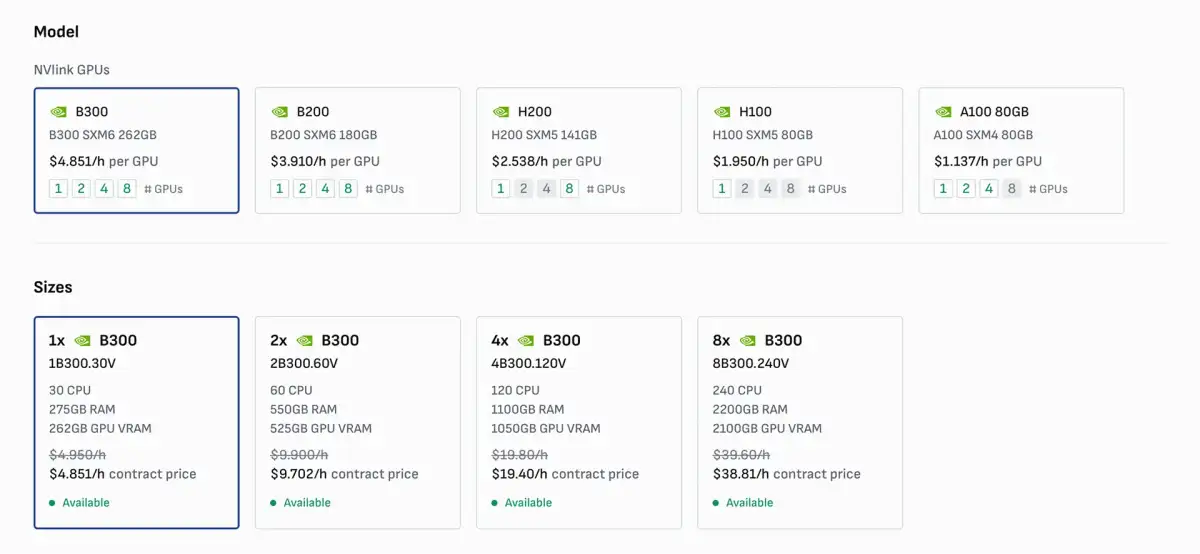
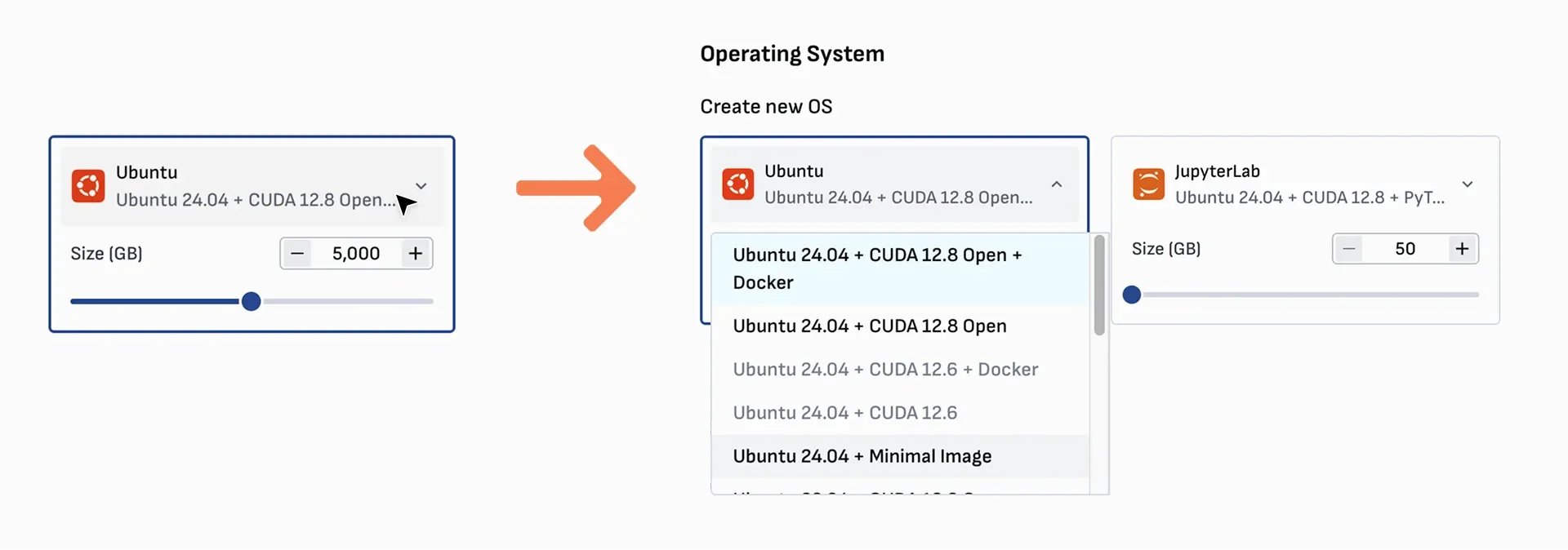
Configuration Options: The process for creating instances involves specifying detailed parameters, such as instance type (e.g., '1V100.6V'), location, operating system image (with CUDA and Docker pre-installed), volume size, and hostnames.
Deployment and Configuration Nuances
The setup of a GPU instance involves several configurable steps, extending beyond just selecting hardware.
SSH Key Management: Secure access is managed through SSH keys, which can be chosen or created during the deployment process.
Startup Scripts: The integration of optional startup scripts allows for automated configuration of instances upon their initial deployment. These are described as bash scripts that run automatically.
Location Selection: While often automated, the choice of datacenter location for an instance is a factor in deployment.
The documentation also touches upon browsing available instance types with their specifications and pricing, including "spot pricing," which suggests a tiered or variable cost structure for accessing these computational resources. Operating system images and available datacenter locations are also browseable.
Underlying Infrastructure and Orchestration
The emergence of platforms like NVIDIA Run:ai and the detailed instance management tools from Verda suggest an underlying trend. It is not just about having access to powerful GPUs, but about efficiently deploying and managing them to handle the complex, often variable demands of modern AI development. This orchestration aims to reduce friction in the AI lifecycle, from initial experimentation to large-scale deployment. The use of templates for instance creation further streamlines this process, allowing for reproducible and standardized deployments.
Read More: New vLLM Software Makes AI Models Run Much Faster



