Slowness and Device Errors Hamper Progress
Concerns are surfacing regarding the computational demands and hardware limitations hindering the practical application of AI model distillation, particularly on widely accessible platforms. Reports indicate that processes involving GPU credits are proving "painfully slow," with some tasks taking upwards of 15 hours to complete. This sluggish performance is compounded by specific runtime errors when attempting to deploy certain models, such as the DeepSeek-R1-Distill-Llama-8B-SAE-l19, on NVIDIA T4 GPUs within environments like Google Colab.
These errors, often manifesting as "Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False," suggest a mismatch or configuration issue preventing the necessary graphics processing units from being recognized or utilized effectively for model loading. This directly impacts the feasibility of running advanced AI techniques.

Model Distillation Explained
The core challenge appears to be tied to 'model distillation,' a technique used to create smaller, more efficient AI models by transferring knowledge from larger, more complex ones. This process, often described using a 'teacher-student' paradigm, aims to reduce the cost and operational overhead associated with deploying powerful AI, as seen with models like 'ChatGPT'. Libraries like DistillFlow facilitate this by supporting various distillation strategies, including 'logits', 'attention', and 'layer-based' methods, and offer optimizations through tools like 'Unsloth' and 'Flash Attention'.
Read More: MIT Boron-Oxygen Molecule Acts as Builder in Chemical Reactions
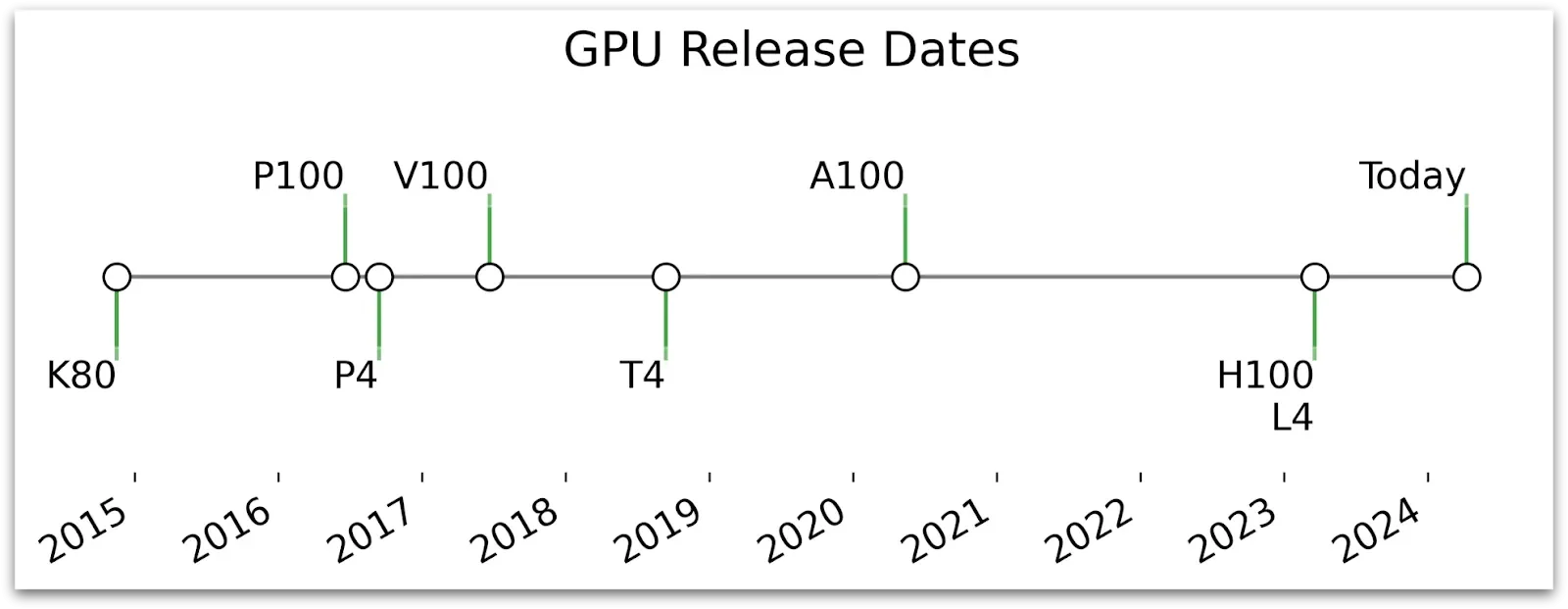
Hardware Bottlenecks: The NVIDIA T4
The NVIDIA T4 GPU, while designed to accelerate diverse cloud workloads including deep learning, is evidently showing its limitations in this context. Its "energy-efficient 70-watt, small PCIe form factor" might not possess the raw power or specific configurations needed for the more demanding distillation tasks. Anecdotal evidence suggests that for substantial fine-tuning of Large Language Models (LLMs), even in a single GPU setup, options like the A100 might be more suitable, though these are not always readily available or affordable on platforms like Colab, where the T4 is a common free or paid offering.
The DeepSeek-R1 Case
Specific models, like the 'DeepSeek-R1-Distill-Llama-70B', are architecturally complex. Built on a dense transformer model and employing mechanisms like Multi-Head Attention with a significant number of heads and Flash Attention for optimization, these models still require substantial computational resources. The difficulties encountered when running these on T4 GPUs, even with pre-set configurations, highlight the gap between the capabilities of readily available hardware and the growing demands of sophisticated AI models and techniques.
Read More: Anthropic Refuses China Access to Latest AI Models