
Google's 'MediaPipe LLM Inference API' is enabling the operation of Large Language Models (LLMs) directly on Android devices. This development, intended for experimental and research use, allows for on-device AI processing across various platforms, a feat made possible by significant optimizations within the on-device stack. These include new operational components, quantization techniques, caching mechanisms, and weight sharing. The API supports model weights compatible with its architecture, broadening the scope of usable models.
The 'MediaPipe LLM Inference API' offers a simplified route for integrating LLMs into Android applications, supporting both standard model paths and remote URLs for model weights. Developers can implement this by configuring LlmInferenceOptions, specifying parameters like the model path, maximum tokens, temperature, and optionally a LoRA (Low-Rank Adaptation) path for model fine-tuning. The process involves creating an instance of the LlmInference task using these options and then employing methods such as generateResponse() or generateResponseAsync() to interact with the model.
Read More: Why AI Agents Forget Data in May 2026 and How Engineers Fix It
The 'MediaPipe Samples' repository provides a functional Android demo application, tested with 'Android Studio Hedgehog'. Building this demo requires a physical Android device running a minimum OS version of 'SDK 24' ('Android 7.0 - Nougat') with developer mode activated. The application itself follows a modern Android architecture, utilizing 'Jetpack Compose' for its user interface and the 'MVVM (Model-View-ViewModel)' pattern for state management.
Key constants and methods are defined within the InferenceModel class, which manages the core LLM operations. These include MAX_TOKENS for response length limits and DECODE_TOKEN_OFFSET to ensure sufficient response capacity. Core methods include createEngine() for loading models, createSession() for setting up inference parameters, generateResponseAsync() for processing prompts, and estimateTokensRemaining() for calculating available context.
Read More: iOS 26.5 Update Causes iPhone Battery Drain May 2026

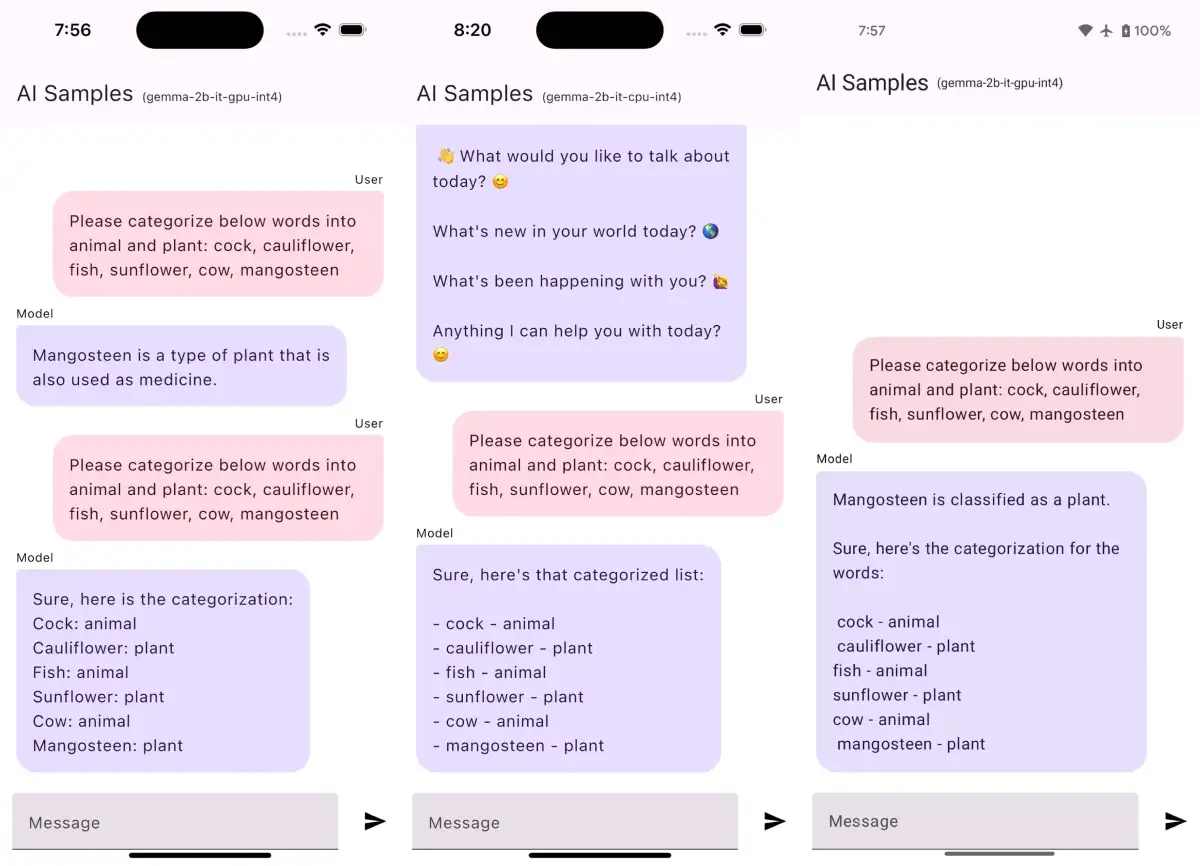
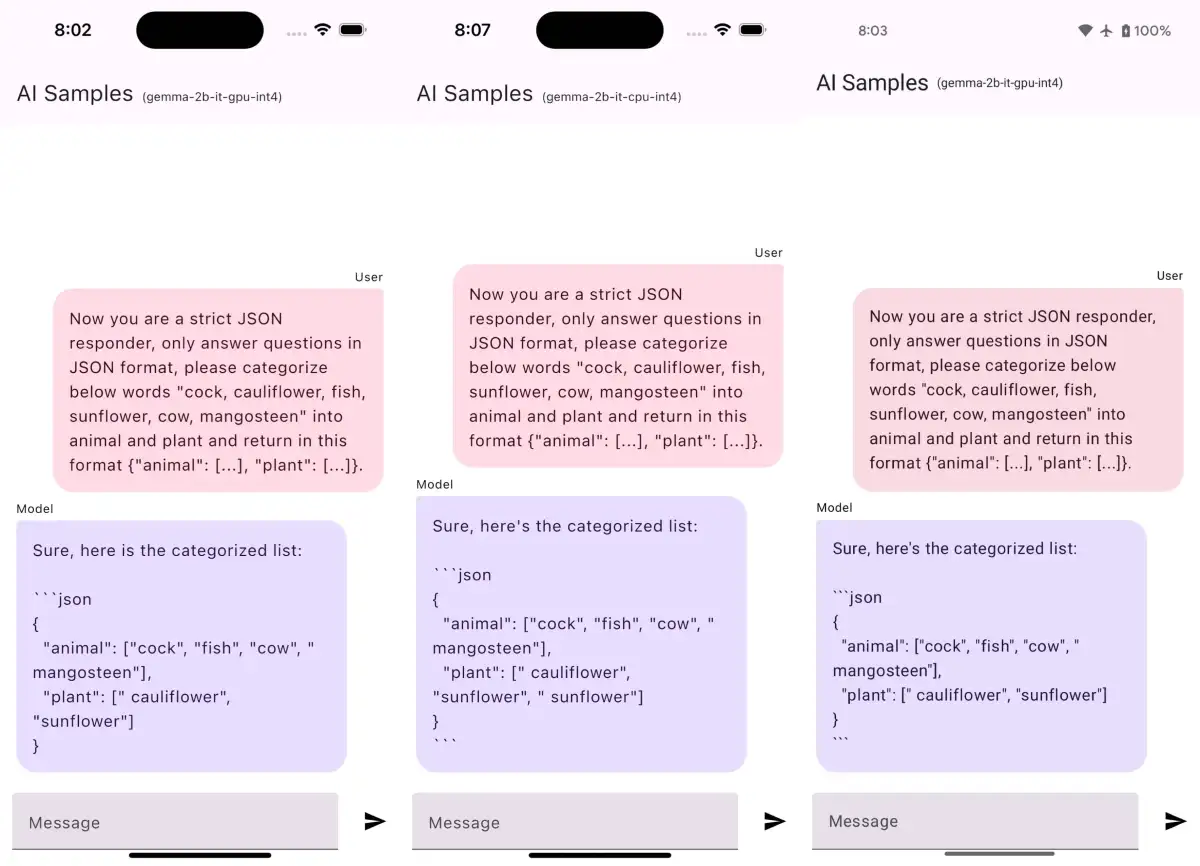
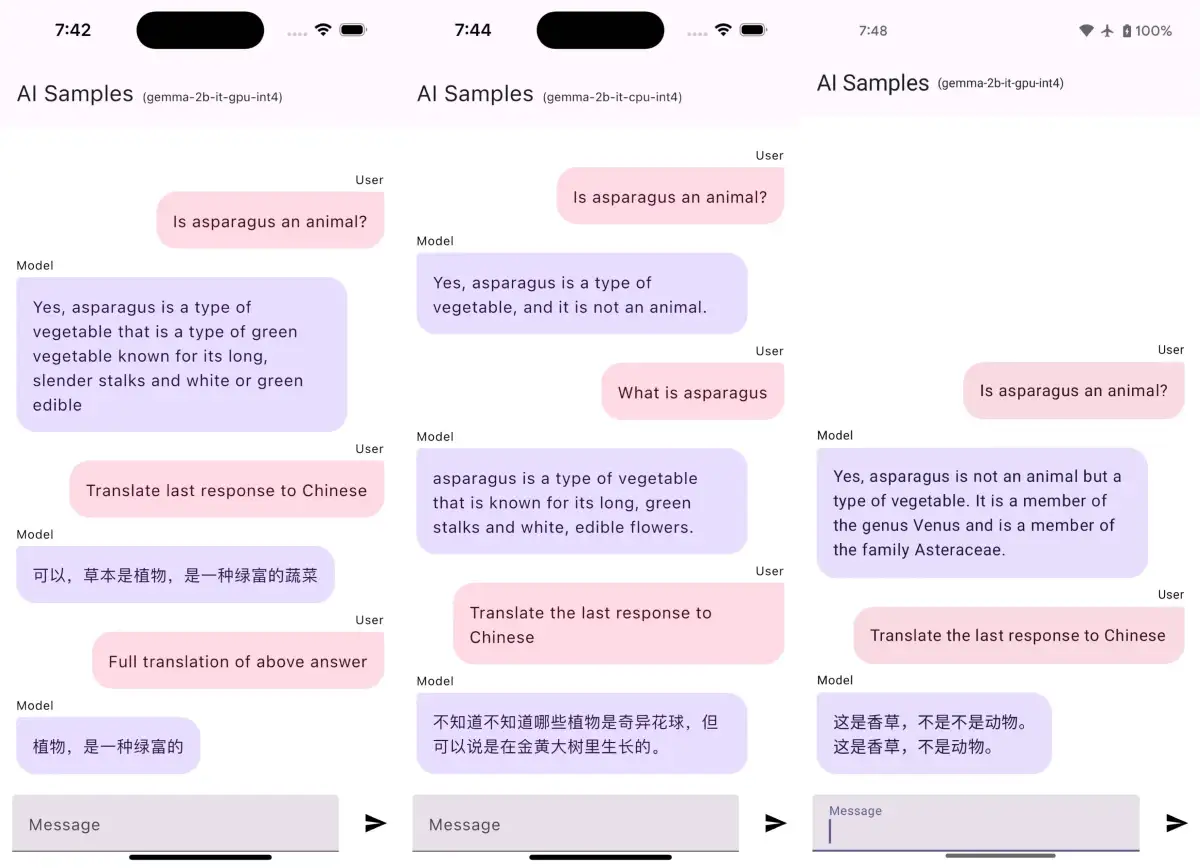
The Model enum within the repository outlines available LLM options, such as 'Gemma 3 1B', 'DeepSeek', and 'Phi-4 Mini', specifying their intended hardware backend (CPU or GPU) and any authentication requirements. Some models, like 'Gemma', necessitate authentication with 'Hugging Face' for model downloads. The system handles various UI states, with specific implementations for different models, ensuring proper prompt formatting and state management during interactions. The application navigation is managed through 'Jetpack Navigation', featuring distinct screens for loading processes and user interaction.
The integration extends to advanced use cases, including the adaptation of MediaPipe demos for 'Kotlin Multiplatform' projects. Specific tests have highlighted performance differences between CPU and GPU versions of models like 'Gemma 2B', with the CPU version sometimes providing more reasonable outputs. The framework's architecture supports customization, such as adapting resource loading methods from R to Res for 'Compose Multiplatform'.
Read More: What are Copilot+ PCs and how do they differ from AI PCs in 2026?
The 'MediaPipe LLM Inference API' is presented as a straightforward method to incorporate LLMs onto devices, with optimizations aiming to enhance performance. It's noted that the framework has been evolving, with guidance available for converting other models and running LLM inference with LoRA adapters. The project is under active development, with releases and examples continually updated.




