
Hidden Links in High-Volume Datasets Revealed
Researchers have forged a new analytical approach, dubbed 'j-LANCE,' designed to untangle intricate relationships within large, multi-faceted datasets. This Bayesian inference technique allows for the simultaneous examination of dependencies across different groups within data that has a multitude of variables. The method specifically addresses the growing challenge of analyzing complex information streams in fields like genomics, climate science, finance, and sensor technology. The work, detailed in the journal Bayesian Analysis, builds upon existing statistical frameworks by employing a Markov random field prior. This component enables the model to discern both shared patterns and unique structures that emerge across distinct data cohorts.
Capturing Shared and Distinctive Patterns
The j-LANCE system demonstrated its capability by identifying consistent trends over time while simultaneously flagging unique dependencies that materialized in specific periods. This dual-focus ability is crucial for understanding dynamic systems where overarching similarities coexist with isolated, time-bound events. The researchers highlight that this confirmed the technique's utility with real-world data.
Read More: Computer Graphics Problems After BIOS Update
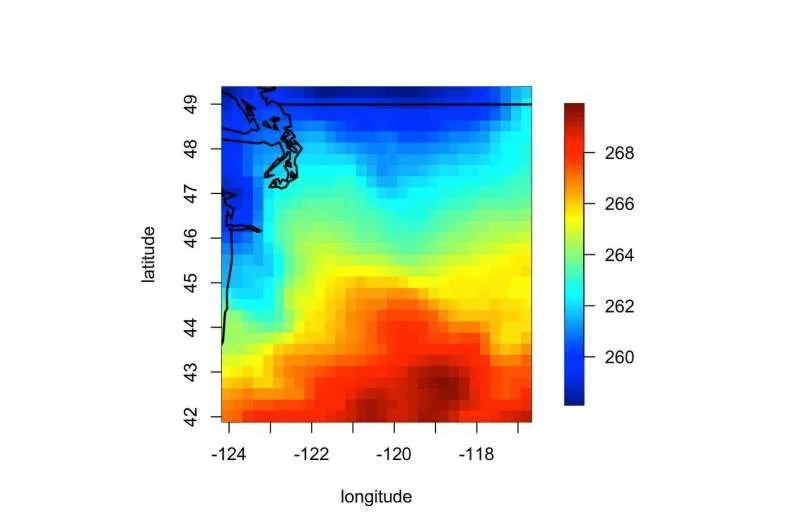
Implications for Diverse Disciplines
The development signals a potential leap forward for analyzing complex, group-based information. Its application is envisioned across a broad spectrum of scientific and industrial domains. These include:
Climate Studies: Understanding how atmospheric or oceanic variables interact and evolve across different regions or timeframes.
Genomics: Mapping gene expression patterns and their interdependencies within various biological samples or experimental conditions.
Finance: Detecting intricate correlations in market data across different asset classes or geographic locations.
Sensor Networks: Analyzing simultaneous readings from numerous sensors to identify coordinated or anomalous behaviors.
Background: The Data Deluge and the Need for Sophistication
The contemporary landscape is characterized by an exponential rise in high-dimensional data. These datasets, where numerous variables are recorded concurrently, present a significant analytical hurdle. Traditional methods often struggle to effectively navigate this complexity, particularly when seeking to understand relationships across distinct subsets or groups within the data. Previous research has explored various statistical models for such tasks, including 'Bayesian Hidden Markov Models' that attempt to address dependence in large-scale hypothesis testing, as noted in studies found on platforms like PubMed Central. The j-LANCE method appears to offer a more refined and flexible tool for excavating these often-obscured connections.



